Что делать дальше?
И вот мы подбираемся к самому интересному: а где хранить пароли и в каком виде? Давайте сначала подумаем, где их хранить.
Что такое сессии?
Попробую рассказать в паре абзацев.
Сессии — это механизм, который позволяет однозначно идентифицировать пользователя.
По-человечески это значит, что для каждого посетителя сайта можно создать уникальное «хранилище», к которому будет доступ только у этого самого посетителя.
Хранилище это хранится в файле на сервере.
На самом деле сессии хранятся не обязательно в файлах. Например, cms Modx хранит их базе данных.
Но сейчас нам это не важно, главное, что сессии предоставляют удобный способ работать с данными, уникальными для пользователя.
Для нас сессия выглядит как обычный ассоциативный массив под названием $_SESSION, в разные поля которого можно записать хоть число, хоть строку, хоть сериализованный объект.
Fetch: запросы на другие сайты
Если мы сделаем запрос fetch на другой веб-сайт, он, вероятно, завершится неудачей.
Например, давайте попробуем запросить http://example.com:
Вызов fetch не удался, как и ожидалось.
Ключевым понятием здесь является источник (origin) – комбинация домен/порт/протокол.
Запросы на другой источник – отправленные на другой домен (или даже поддомен), или протокол, или порт – требуют специальных заголовков от удалённой стороны.
Эта политика называется «CORS»: Cross-Origin Resource Sharing («совместное использование ресурсов между разными источниками»).
CORS существует для защиты интернета от злых хакеров.
Серьёзно. Давайте сделаем краткое историческое отступление.
Многие годы скрипт с одного сайта не мог получить доступ к содержимому другого сайта.
Это простое, но могучее правило было основой интернет-безопасности. Например, хакерский скрипт с сайта hacker.com не мог получить доступ к почтовому ящику пользователя на сайте gmail.com. И люди чувствовали себя спокойно.
В то время в JavaScript не было методов для сетевых запросов. Это был «игрушечный» язык для украшения веб-страниц.
Но веб-разработчики жаждали большей власти. Чтобы обойти этот запрет и всё же получать данные с других сайтов, были придуманы разные хитрости.
Одним из способов общения с другим сервером была отправка туда формы <form>. Люди отправляли её в <iframe>, чтобы оставаться на текущей странице, вот так:
Таким способом было возможно сделать GET/POST запрос к другому сайту даже без сетевых методов, так как формы можно отправлять куда угодно. Но так как запрещено получать доступ к содержимому <iframe> с другого сайта, прочитать ответ было невозможно.
Если быть точным, были трюки и для этого, требующие специального кода на странице и в ифрейме, так что общение с ифреймом было технически возможно. Сейчас мы не будем вдаваться в подробности, пусть эти динозавры покоятся в мире.
Ещё один трюк заключался в использовании тега script. У него может быть любой src, с любым доменом, например <script src="https://another.com/…">. Это даёт возможность загрузить и выполнить скрипт откуда угодно.
Если сайт, например another.com, хотел предоставить данные для такого доступа, он предоставлял так называемый «протокол JSONP» (JSON with Padding)».
Вот как он работал.
Например, нам на нашем сайте нужны данные с сайта http://another.com, скажем, погода:
Сначала, заранее, объявляем глобальную функцию для обработки данных, например
gotWeather.Затем создаём тег
<script>сsrc="http://another.com/weather.json?callback=gotWeather", при этом имя нашей функции – в URL-параметреcallback.Удалённый сервер с
another.comдолжен в ответ сгенерировать скрипт, который вызываетgotWeather(...)с данными, которые хочет передать.Когда этот скрипт загрузится и выполнится, наша функция
gotWeatherполучает данные.
Это работает и не нарушает безопасность, потому что обе стороны согласились передавать данные таким образом. А когда обе стороны согласны, то это определённо не хак. Всё ещё существуют сервисы, которые предоставляют такой доступ, так как это работает даже для очень старых браузеров.
Спустя некоторое время в браузерном JavaScript появились методы для сетевых запросов.
Вначале запросы на другой источник были запрещены. Но в результате долгих дискуссий было решено разрешить их делать, но для использования новых возможностей требовать разрешение сервера, выраженное в специальных заголовках.
Есть два вида запросов на другой источник:
- Простые.
- Все остальные.
Простые запросы будут попроще, поэтому давайте начнём с них.
Простой запрос – это запрос, удовлетворяющий следующим условиям:
- Простой метод: GET, POST или HEAD
- Простые заголовки – разрешены только:
Accept,Accept-Language,Content-Language,Content-Typeсо значениемapplication/x-www-form-urlencoded,multipart/form-dataилиtext/plain.
Любой другой запрос считается «непростым». Например, запрос с методом PUT или с HTTP-заголовком API-Key не соответствует условиям.
Принципиальное отличие между ними состоит в том, что «простой запрос» может быть сделан через <form> или <script>, без каких-то специальных методов.
Таким образом, даже очень старый сервер должен быть способен принять простой запрос.
В противоположность этому, запросы с нестандартными заголовками или, например, методом DELETE нельзя создать таким способом. Долгое время JavaScript не мог делать такие запросы. Поэтому старый сервер может предположить, что такие запросы поступают от привилегированного источника, «просто потому, что веб-страница неспособна их посылать».
Когда мы пытаемся сделать непростой запрос, браузер посылает специальный предварительный запрос («предзапрос», по англ. «preflight»), который спрашивает у сервера – согласен ли он принять такой непростой запрос или нет?
И, если сервер явно не даёт согласие в заголовках, непростой запрос не посылается.
Далее мы разберём конкретные детали.
При запросе на другой источник браузер всегда ставит «от себя» заголовок Origin.
Например, если мы запрашиваем https://anywhere.com/request со страницы https://javascript.info/page, заголовки будут такими:
Как вы можете видеть, заголовок Origin содержит именно источник (домен/протокол/порт), без пути.
Сервер может проверить Origin и, если он согласен принять такой запрос, добавить особый заголовок Access-Control-Allow-Origin к ответу. Этот заголовок должен содержать разрешённый источник (в нашем случае https://javascript.info) или звёздочку *. Тогда ответ успешен, в противном случае возникает ошибка.
Здесь браузер играет роль доверенного посредника:
- Он гарантирует, что к запросу на другой источник добавляется правильный заголовок
Origin. - Он проверяет наличие разрешающего заголовка
Access-Control-Allow-Originв ответе и, если всё хорошо, то JavaScript получает доступ к ответу сервера, в противном случае – доступ запрещается с ошибкой.
Вот пример ответа сервера, который разрешает доступ:
По умолчанию при запросе к другому источнику JavaScript может получить доступ только к так называемым «простым» заголовкам ответа:
Cache-ControlContent-LanguageContent-TypeExpiresLast-ModifiedPragma
При доступе к любому другому заголовку ответа будет ошибка.
Чтобы разрешить JavaScript доступ к любому другому заголовку ответа, сервер должен указать заголовок Access-Control-Expose-Headers. Он содержит список, через запятую, заголовков, которые не являются простыми, но доступ к которым разрешён.
Например:
При таком заголовке Access-Control-Expose-Headers, скрипту разрешено получить заголовки Content-Length и API-Key ответа.
Мы можем использовать любой HTTP-метод: не только GET/POST, но и PATCH, DELETE и другие.
Некоторое время назад никто не мог даже предположить, что веб-страница способна делать такие запросы. Так что могут существовать веб-сервисы, которые рассматривают нестандартный метод как сигнал: «Это не браузер». Они могут учитывать это при проверке прав доступа.
Поэтому, чтобы избежать недопониманий, браузер не делает «непростые» запросы (которые нельзя было сделать в прошлом) сразу. Перед этим он посылает предварительный запрос, спрашивая разрешения.
Предварительный запрос использует метод OPTIONS, у него нет тела, но есть три заголовка:
Если сервер согласен принимать такие запросы, то он должен ответить без тела, со статусом 200 и с заголовками:
Access-Control-Allow-Originдолжен содержать разрешённый источник.Access-Control-Allow-Methodsдолжен содержать разрешённые методы.Access-Control-Allow-Headersдолжен содержать список разрешённых заголовков.- Кроме того, заголовок
Access-Control-Max-Ageможет указывать количество секунд, на которое нужно кешировать разрешения. Так что браузеру не придётся посылать предзапрос для последующих запросов, удовлетворяющих данным разрешениям.
Давайте пошагово посмотрим, как это работает, на примере PATCH запроса (этот метод часто используется для обновления данных) на другой источник:
Этот запрос не является простым по трём причинам (достаточно одной):
- Метод
PATCH Content-Typeне один из:application/x-www-form-urlencoded,multipart/form-data,text/plain.- Содержит «непростой» заголовок
API-Key.
Перед тем, как послать такой запрос, браузер самостоятельно генерирует и посылает предзапрос, который выглядит следующим образом:
- Метод:
OPTIONS. - Путь – точно такой же, как в основном запросе:
/service.json. - Особые заголовки:
Origin– источник.Access-Control-Request-Method– запрашиваемый метод.Access-Control-Request-Headers– разделённый запятыми список «непростых» заголовков запроса.
Сервер должен ответить со статусом 200 и заголовками:
Access-Control-Allow-Methods: PATCHAccess-Control-Allow-Headers: Content-Type,API-Key.
Это разрешит будущую коммуникацию, в противном случае возникает ошибка.
Если сервер ожидает в будущем другие методы и заголовки, то он может в ответе перечислить их все сразу, разрешить заранее, например:
Теперь, когда браузер видит, что PATCH есть в Access-Control-Allow-Methods, а Content-Type,API-Key – в списке Access-Control-Allow-Headers, он посылает наш основной запрос.
Кроме того, ответ на предзапрос кешируется на время, указанное в заголовке Access-Control-Max-Age (86400 секунд, один день), так что последующие запросы не вызовут предзапрос. Они будут отосланы сразу при условии, что соответствуют закешированным разрешениям.
Если предзапрос успешен, браузер делает основной запрос. Алгоритм здесь такой же, что и для простых запросов.
Основной запрос имеет заголовок Origin (потому что он идёт на другой источник):
Сервер не должен забывать о добавлении Access-Control-Allow-Origin к ответу на основной запрос. Успешный предзапрос не освобождает от этого:
После этого JavaScript может прочитать ответ сервера.
Запрос на другой источник по умолчанию не содержит авторизационных данных (credentials), под которыми здесь понимаются куки и заголовки HTTP-аутентификации.
Это нетипично для HTTP-запросов. Обычно запрос к http://site.com сопровождается всеми куки с этого домена. Но запросы на другой источник, сделанные методами JavaScript – исключение.
Например, fetch('http://another.com') не посылает никаких куки, даже тех (!), которые принадлежат домену another.com.
Почему?
Потому что запрос с авторизационными данными даёт намного больше возможностей, чем без них. Если он разрешён, то это позволяет JavaScript действовать от имени пользователя и получать информацию, используя его авторизационные данные.
Действительно ли сервер настолько доверяет скрипту? Тогда он должен явно разрешить такие запросы при помощи дополнительного заголовка.
Чтобы включить отправку авторизационных данных в fetch, нам нужно добавить опцию credentials: "include", вот так:
Теперь fetch пошлёт куки с домена another.com вместе с нашим запросом на этот сайт.
Если сервер согласен принять запрос с авторизационными данными, он должен добавить заголовок Access-Control-Allow-Credentials: true к ответу, в дополнение к Access-Control-Allow-Origin.
Например:
Пожалуйста, обратите внимание: в Access-Control-Allow-Origin запрещено использовать звёздочку * для запросов с авторизационными данными. Там должен быть именно источник, как показано выше. Это дополнительная мера безопасности, чтобы гарантировать, что сервер действительно знает, кому он доверяет делать такие запросы.
С точки зрения браузера запросы к другому источнику бывают двух видов: «простые» и все остальные.
Простые запросы должны удовлетворять следующим условиям:
- Метод: GET, POST или HEAD.
- Заголовки – мы можем установить только:
AcceptAccept-LanguageContent-LanguageContent-Typeсо значениемapplication/x-www-form-urlencoded,multipart/form-dataилиtext/plain.
Основное их отличие заключается в том, что простые запросы с давних времён выполнялись с использованием тегов <form> или <script>, в то время как непростые долгое время были невозможны для браузеров.
Практическая разница состоит в том, что простые запросы отправляются сразу с заголовком Origin, а для других браузер делает предварительный запрос, спрашивая разрешения.
Для простых запросов:
- → Браузер посылает заголовок
Originс источником. - ← Для запросов без авторизационных данных (не отправляются по умолчанию) сервер должен установить:
Access-Control-Allow-Originв*или то же значение, что иOrigin
- ← Для запросов с авторизационными данными сервер должен установить:
Access-Control-Allow-Originв то же значение, что иOriginAccess-Control-Allow-Credentialsвtrue
Дополнительно, чтобы разрешить JavaScript доступ к любым заголовкам ответа, кроме Cache-Control, Content-Language, Content-Type, Expires, Last-Modified или Pragma, сервер должен перечислить разрешённые в заголовке Access-Control-Expose-Headers.
Для непростых запросов перед основным запросом отправляется предзапрос:
- → Браузер посылает запрос
OPTIONSна тот же адрес с заголовками:Access-Control-Request-Method– содержит запрашиваемый метод,Access-Control-Request-Headers– перечисляет непростые запрашиваемые заголовки.
- ← Сервер должен ответить со статусом 200 и заголовками:
Access-Control-Allow-Methodsсо списком разрешённых методов,Access-Control-Allow-Headersсо списком разрешённых заголовков,Access-Control-Max-Ageс количеством секунд для кеширования разрешений
- → Затем отправляется основной запрос, применяется предыдущая «простая» схема.
Автоматическое использование браузера
Этот подход популярен у начинающих скрейперов настолько, что они переходят к нему каждый раз, как сталкиваются с трудностями при анализе сайта. Профессионалы с жёсткими дедлайнами также любят этот подход.
Главный плюс такого подхода – простота прохождения скриптовой защиты, так как в скриптах сайта нет необходимости разбираться – они просто выполнятся в браузере и сделают всё то же самое, как если бы их запускал не ваш код, а пользователь с мышкой и клавиатурой.
Главный минус этого подхода – вы запускаете чужой код у себя на компьютере. Этот код может, например, содержать дополнительную защиту от автоматизации самого разного типа от детекторов headless-браузеров и до интеллектуального анализа поведения пользователей.
Выбираем правильное хэширование
Идею хранения паролей нашли, то есть хранения не паролей, а их хэшей. А вот какой алгоритм хэширования выбрать?
Давайте посмотрим на то, что пробовали выше — простая функция md5. Алгоритма его расшифровки нет, но тем не менее md5 не рекомендуется для использования. Почему?
Помимо сложности самого алгоритма, есть и другой момент. Да, расшифровать пароль по хэшу нельзя, но его можно подобрать. Простым брутфорсом.
К тому же существуют многочисленные базы паролей md5, где всевозможные варианты хранятся тупо списком.
И подбор вашего пароля по известному хэшу займет столько времени, сколько понадобится для выполнения sql-запроса
select password from passwords where hash='e10adc3949ba59abbe56e057f20f883e';
Конечно, вы сами не будете использовать пароль 123456, но как насчет ваших пользователей? Да, 123456 можно подобрать и руками, но в таком случае никакие алгоритмы не помогут.
Наша же задача максимально позаботиться о юзерах, которые выбирают пароли сложнее qwerty. Думаем дальше, гуглим.
Помимо md5 есть множество алгоритмов хэширования, sha256, sha512 и еще целая толпа. Их сложность выше, но это не отменяет опять-таки существования таблиц с готовыми паролями.
Нужно что-то хитрее.
Заглушка для авторизации
Функции, связанные с авторизацией, будут лежать в отдельном файле и своем пространстве имен. Создадим файл auth.php в api/v1/common — там, где уже лежит helpers.php.
Если вы разбирали уроки админки, особенно третий, про серверную часть, то эти пути вам будут знакомы. Если у вас свой проект, то кладите auth.php куда удобно.
Главное, потом правильно указать пути.
Содержимое auth.php
И напоследок
CASL написан на чистом ES6, поэтому его можно использовать для авторизации как на API так и на UI стороне. Дополнительным плюсом является то, что UI может запросить все права доступа с API, и использовать их, чтобы показать или скрыть кнопки или целые секции на странице.
Интеграция с базой данных
CASL предоставляет функции, которые позволяют преобразовывать описанные права доступа в запросы к базе данных. Таким образом можно достаточно легко получить все записи из базы, к которым пользователь имеет доступ. На данный момент библиотека поддерживает только MongoDB и предоставляет средства для написания интеграции с другими языками запросов.
Для конвертации прав доступа в Mongo запрос существует toMongoQuery функция:
Как обойтись без шифрования. хэширование
Фокус в том, что не нужно хранить пароли в открытом виде, но и не нужно шифровать их с возможностью расшифровки. Пароли нужно хэшировать и в базе хранить не пароль, а его хэш.
Хитрым образом закодированную строку, которую нельзя расшифровать. Например, не password, а 5f4dcc3b5aa765d61d8327deb882cf99
Вы можете спросить, что это за хрень и как же сравнить пароль, введенный пользователем, с паролем, лежащим в базе. А нам и не нужно сравнивать пароли — достаточно сравнить их хэши.
Например, есть простая функция хэширования md5. Вот так она работает
Клиентская авторизация
С клиентской авторизацией действительно нет ничего сложного.
Согласно
, достаточно асинхронно загрузить
и, «повесить»
VK.init({appid: YOUR_APP_ID})
на событие
window.vkAsyncInit
, после чего уже можно вызвать функцию
VK.Auth.login(authInfo, YOUR_APP_PERMISSIONS)
, которая и выполнит авторизацию пользователя.
var vk = { data: {}, api: "//vk.com/js/api/openapi.js", appID: YOUR_APP_ID, appPermissions: YOUR_APP_PERMISSIONS, init: function(){ $.js(vk.api); window.vkAsyncInit = function(){ VK.init({apiId: vk.appID}); load(); } function load(){ VK.Auth.login(authInfo, vk.appPermissions); function authInfo(response){ if(response.session){ // Авторизация успешна vk.data.user = response.session.user; vk.getFriends(); }else alert("Авторизоваться не удалось!"); } } }, getFriends: function(){ VK.Api.call('friends.get', {fields: ['uid', 'first_name', 'last_name'], order: 'name'}, function(r){ if(r.response){ r = r.response; var ol = $('#clientApi').add('ol'); for(var i = 0; i < r.length; i){ var li = ol.add('li').html(r[i].first_name ' ' r[i].last_name ' (' r[i].uid ')') } }else alert("Не удалось получить список ваших друзей"); }) }
}
$.ready(vk.init);Во-первых, сразу оговорюсь, что используемые здесь функции
$
— это не
jQuery
. Тем не менее, их назначение может не быть интуитивно понятным, так что я буду рассказывать, что же делает та или иная функция. Их самостоятельная реализация не должна составить особого труда, ровно как и перекладка всего кода на
jQuery
.
Итак,$.ready(function) — Это обработчик для DOMContentLoaded;$.js(text) — асинхронно загружает javascript файл;$(element) — возвращает обёртку над DOM узлом element;$(element).add(node) — создаёт новый дочерний для element узел node и возвращает обёртку над ним;$(element).html(string) — обёртка для element.innerHTML = string.
По-сути, этот код делает следующее:
По готовности документа загружается API ВКонтакте, и, после его инициализации, вызывается метод
VK.Auth.login()
, который показывает всплывающее окно,
которое успешно «блочится» любой баннерорезкой
, в котором пользователь должен подтвердить своё согласие предоставить данные клиентскому приложению.
Функция
authInfo
вызывается после согласия или несогласия пользователя, и, в случае успешной авторизации, запрашивает список друзей.
Клиентскую часть таким образом можно считать законченной, однако, стоит как-то предупреждать пользователей о возможности блокировки их браузером окна подтверждения.
Краткий обзор методов
Все методы решения подобных задач можно условно разделить на три категории:
- Имитация браузера: выполнение запросов на основе данных полученных хакерскими методами, такими как анализ трафика, реверс-инжиниринг скриптов и так далее.
- Автоматическое использование браузера. Сюда относится управление из скрипта настоящими браузерами (например, Chrome) через специальный API (например, с помощью Selenium WD), а также использование headless-браузеров (например PhantomJS).
- Использование браузера вручную. Это не обязательно означает полный отказ от автоматизации скрейпинга, но подразумевает, что живой оператор будет видеть реальные страницы и выполнять на них реальные действия через пользовательский интерфейс.
Выбор из этих трёх пунктов – не очевиден и как минимум субъективен. Все три категории имеют свои плюсы и минусы и любая из них позволяет решить нашу задачу, так что рассмотрим их по очереди.
Постановка задачи
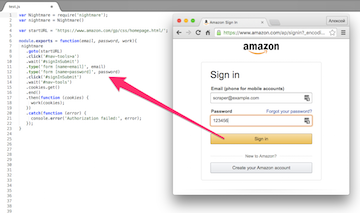 На этот раз заказчик – другой веб-скрейпер, которому понадобилась помощь коллеги. Он хочет получить (для своего заказчика) данные с известного сайта Amazon. Некоторые из нужных ему данных отдаются только авторизованным пользователям. Разумеется, у заказчика есть аккаунт на Amazon, но проблема в том, что на этом сайте реализована защита от автоматической авторизации. Заказчику нужен модуль на Node.js, который эту защиту проходит. Естественно, речь идёт об инструменте для автоматической авторизации своим аккаунтом под свою ответственность, а не о взломе чужого аккаунта, например.
На этот раз заказчик – другой веб-скрейпер, которому понадобилась помощь коллеги. Он хочет получить (для своего заказчика) данные с известного сайта Amazon. Некоторые из нужных ему данных отдаются только авторизованным пользователям. Разумеется, у заказчика есть аккаунт на Amazon, но проблема в том, что на этом сайте реализована защита от автоматической авторизации. Заказчику нужен модуль на Node.js, который эту защиту проходит. Естественно, речь идёт об инструменте для автоматической авторизации своим аккаунтом под свою ответственность, а не о взломе чужого аккаунта, например.
Проверяем возможности
Существует 3 метода у экземпляра Ability, которые позволяют проверять права доступа:
import { ForbiddenError } from 'casl'
ability.can('update', 'Post')
ability.cannot('update', 'Post')
try { ability.throwUnlessCan('update', 'Post')
} catch (error) { console.log(error instanceof Error) // true console.log(error instanceof ForbiddenError) // true
}Первый метод вернет false, второй true, а третий выбросит ForbiddenError для анонимного пользователя, так как они не имеют права обновлять статьи. В качестве второго аргумента, эти методы могут принимать экземпляр класса:
const post = new Post({ title: 'What is CASL?' })
ability.can('read', post)В этом случае can (‘read’, post) возвращает true, потому что в способностях мы определили, что пользователь может читать все статьи. Тип объекта вычисляется на основе constructor.name. Его можно переопределить создав статическое свойство modelName на классе Post, это может понадобится если для продакшн сборки используется минификация имен функций. Также можно написать свою функцию по определению типа объекта и передать ее как опцию в конструктор Ability:
import { Ability } from 'casl'
function subjectName(subject) { // custom logic to detect subject name, should return string or undefined
}
const ability = new Ability([], { subjectName })Давайте теперь проверим случай, когда пользователь пытается обновить статью другого пользователя (я буду ссылаться на идентификатор другого автора как anotherId и к идентификатору текущего пользователя как myId):
const post = new Post({ title: 'What is CASL?', authorId: 'anotherId' })
ability.can('update', post)В этом случае can(‘update’, post) возвращает false, поскольку мы определили, что пользователь может обновлять только свои собственные статьи. Конечно же, если проверить то же самое на собственной статье то получим true. Подробнее о проверках прав доступа можно посмотреть в разделе Check Abilities в официальной документации.
Проверяем работоспособность vue
Вроде бы, чего там может сломаться? Нам же практически не пришлось лезть в код vue, за исключением добавления кнопки Выйти в шапке админки.
Но попробуем пересобрать админку, чтобы убедиться, что все хорошо. Сначала в production режиме
npm run build
Серверная авторизация
Серверная авторизация гораздо веселее. Механизм серверной авторизации для доступа к ВКонтакте API с стороннего сайта создан на базе протокола OAuth 2.0.
Процесс авторизации происходит следующим образом:
- Необходимо в браузере пользователя показать страницу, где он разрешит приложению доступ к своим данным;
- После успешной авторизации приложения браузер пользователя будет перенаправлен по адресу REDIRECT_URI, указанному при открытии диалога авторизации. При этом в GET-параметре будет передан код для получения ключа доступа;
- Необходимо выполнить запрос с передачей кода и секретных данных приложения на специальный адрес, в ответ мы получим ключ доступа access_token, необходимый нам для совершения запросов к API.
К сожалению, второй пункт, а именно, перенаправление браузера, срабатывает далеко не всегда, точнее, не срабатывает нигде, кроме ИЕ, в тот самый первый раз, когда пользователь впервые разрешает приложению доступ к своим данным. И как только не извращаются разработчики, лишь бы получить заветный код.
К тому же, открытие дополнительного окна опять-таки связано с опасностью, что оно будет заблокировано.
К счастью, если мы знаем ссылку, по которой нужно открыть окно, есть много хороших способов открыть его так, чтобы оно не было заблокировано. Например, старый добрый тег iframe всё ещё в строю стандарта HTML, и он как нельзя лучше подходит для нашей задачи.
Во-первых, раз мы знаем адрес, то мы можем и открыть фрейм и показать пользователю ссылку, где можно всё проделать вручню.
Во-вторых, если-таки происходит редирект, и в фрейме открывается страница с нашего домена, то мы можем получить из фрейма доступ к главному окну и автоматически запустить функцию закрытия фрейма. При этом на сервере уже будет access_token, который мы сохраним в сессии и выполняя с главного окна запросы к серверу сможем получать ответы. Перезагрузки страницы при этом не произойдёт, что полностью решает нашу задачу.
В-третьих, если перенаправления не произошло, и пользователь вручную открыл страницу подтверждения доступа приложения, то там уже точно происходит редирект, на страницу с нашего домена, которая будет открыта не во фрейме, а вместо главной. К сожалению, это и есть перезагрузка, но это меньшая жертва, чем могло бы быть. С этой страницы можно отправить пользователя снова на главную, во второй раз авторизация пройдёт уже без перезагрузок.
Реализацию класса доступа к VK API по OAuth на PHP можно легко найти на гитхабе, что я и сделал (PHP >= 5.4).(Совершенно случайно оказалось, что этот класс, скорее всего, написан хабрапользователем vladkens, за что ему огромное спасибо)
Теперь перейдём к самому интересному.
<?php require_once('vk.php'); session_start(); function getPostStr($data, $default = false){ // возврачает строку - значение $_POST[$data] if(!isset($_POST[$data])) return $default; $data = $_POST[$data]; $data = htmlspecialchars(strip_tags(trim($data))); return ($data != "" ? $data : $default); } function error($code, $text, $params = Array()){ $result = Array('error' => Array('code' => $code, 'message' => $text)); if(count($params) > 0) foreach($params as $key => $value) $result['error'][$key] = $value; die(json_encode($result)); } $vkConf = Array( 'appID' => YOUR_APP_ID, 'apiSecret' => YOUR_API_SECRET, 'callbackUrl' => YOUR_DOMAIN . '/auth.php', 'apiSettings' => YOUR_APP_PERMISSIONS ); $vk = (isset($_SESSION['accessToken'])) ? new VK($vkConf['appID'], $vkConf['apiSecret'], $_SESSION['accessToken']) : null; function userIn($vk, $vkConf){ // Авторизация пользователя unset($_SESSION['accessToken']); $vk = new VK($vkConf['appID'], $vkConf['apiSecret']); $authorizeUrl = $vk -> getAuthorizeURL($vkConf['apiSettings'], $vkConf['callbackUrl']); error(-1, "Необходима авторизация ВКонтакте!", Array('url' => $authorizeUrl)); } function getFriends($fields, $order, $vk){ // Получение списка друзей пользователя $userFriends = $vk -> api('friends.get', array('fields' => $fields, 'order' => $order)); $result = Array(); foreach($userFriends['response'] as $key => $value){ $result[] = Array('firstName' => $value['first_name'], 'lastName' => $value['last_name'], 'uid' => $value['uid']); } echo json_encode($result); } $method = strtolower($api -> getStr("method")); switch($method){ case "user.in" : userIn($vk, $vkConf); break; case "friends.get" : getFriends(getPostStr("fields"), getPostStr("order"), $vk); break; default: Api::error(0, "Неверный запрос к Api"); }
?>
Запросы на эту страницу мы будем посылать методом POST, где параметр
method
содержит название метода, который мы хотим выполнить на сервере.
Структура проекта
Проект имеет следующую структуру:
Теория
Аутентификация и авторизация
Понятия «аутентификация» и «авторизация» часто употребляются как синонимы, но на самом деле они обозначают два разных процесса.
Если кратко, то аутентификация — это проверка того, кем является пользователь, т.е. определение того, что пользователь зарегистрирован в нашей системе, о чем, в частности, может свидетельствовать наличие данных пользователя в нашей базе данных. Авторизация же — это процесс определения полномочий пользователя, т.е. того, к чему пользователь имеет доступ, какие данные нашего приложения он может просматривать, редактировать, удалять и т.д.
В качестве примера сравнения аутентификации и авторизации из реальной жизни можно привести систему безопасности аэропорта. Сначала мы предъявляем паспорт для подтверждения нашей личности (аутентификация, идентификация), затем посадочный талон для подтверждения нашего доступа на самолет (авторизация).
Признаки аутентификации:
Признаки авторизации:
Таким образом, для доступа к приложению требуется как аутентификация, так и авторизация. Если пользователь не может подтвердить свою личность (идентичность, identity), он не будет иметь доступа. И даже если пользователь подтвердил свою личность, но не авторизовался, в доступе ему будет отказано.
Токен

Под токеном в рамках настоящей статьи подразумевается JSON Web Token.
JWT — это открытый стандарт (RFC 7519), определяющий компактный и автономный способ безопасной передачи данных между сторонами в виде объекта формата JSON. JWT — это стандарт, т.е. все JWT являются токенами, но не все токены являются JWT.
Заключение
Задача из этой статьи намного сложнее чем всё то, что обычно делают веб-скрейперы в реальной жизни. Однако на современных биржах фриланса часто бывает так, что битву за заказ выигрывает тот, кто первым заявляет, что способен его выполнить быстро и хорошо.
В результате очень выгодно иметь способность брать заказы практически не глядя и не попадать в неприятности с сорванными дедлайнами, проваленными соглашениями, испорченной репутацией и понизившимся рейтингом. Поэтому, даже если скрейпер целыми днями делает элементарные скрипты для получения данных с простых сайтов, полезно быть готовым столкнуться со сложной защитой и не испугаться.
В ближайшее время я планирую написать о скрейпинге регулярно обновляющихся данных, скрейпинге данных больших объёмов, терминологии скрейпинга, а также о моральных и правовых аспектах скрейпинга. Советы и рекомендации по выбору тем особо приветствуются.
Вместо заключения
Проблемы с dev режимом во vue — это неприятный момент. Мы хотим и апишечку подергать, и все удобства vue-cli использовать. И на елку влезть, и ничего не ободрать.
Возможно, есть более изящный способ обойти эти проблемы в dev режиме, но я их пока не нашел. Поэтому приходится подпирать код лишними условиями.