Что такое grab?
Это библиотека для парсинга сайтов. Её основные функции:
Далее я расскажу о каждом пункте более подробно. Для начала поговорим об инициализации рабочего объекта и подготовке сетевого запроса. Приведу пример кода, который запрашивает страницу с яндекса и сохраняет её в файл:
Что есть ещё в grab?
Есть и другие фишки, но я боюсь, что статья слишком большая получится. Главное правило пользователя библиотеки Grab — если что-то непонятно, нужно смотреть в код. Документация пока слабая
Авторизация
Зачастую многие страницы сайта доступны только авторизованным пользователям. Например, список избранного, на выкачивании которого я и предлагаю потренироваться. У Scrapy почему-то нет специального краулера или метода для авторизации, так что есть повод написать собственную миддлварь, в которой будет происходить получение авторизационных кук и патч ими каждого запроса. В самом же пауке переопределён только стартовый url, так что подключим в settings HabrDownloaderMiddleware:
classHabrDownloaderMiddleware(object):
@classmethoddeffrom_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
defprocess_request(self, request, spider):
habra_auth = getattr(spider, 'habra_auth', None)
if habra_auth isnot None:
key, value = habra_auth
request.cookies[key] = value
return None
defspider_opened(self, spider):
data = {'state': '0d67dc108cbf446f83f8de6b43c8c205', 'consumer': 'habrahabr',
'email': 'email', 'password': 'password'}
response = post('https://id.tmtm.ru/login/', json=data)
cookie = response.headers['set-cookie'].split(';')[0].split('=')
setattr(spider, 'habra_auth', cookie)
spider.logger.info('Spider opened: %s'% spider.name)
Библиотека beautifulsoup
BeautifulSoup используется для извлечения информации из файлов HTML и XML. Он предоставляет дерево синтаксического анализа и функции для навигации, поиска или изменения этого дерева синтаксического анализа.
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.
Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
Второй этап парсинга — извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
И сделаем наш первый get-запрос.
И последний этап парсинга — сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
Извлечение информации об изображении
При повторном просмотре страницы мы видим, что изображения лежат внутри тега img, а ссылка на это изображение находится внутри атрибута src. См. Изображение ниже —
Пример: Python BeautifulSoup Extract Image
Python3
Извлечение ссылок
До сих пор мы видели, как извлекать текст, теперь давайте посмотрим, как извлекать ссылки со страницы.
Пример: Python BeatifulSoup извлекает ссылки
Python3
Извлечение текста из тегов
В приведенных выше примерах вы, должно быть, видели, что при очистке данных теги также очищаются, но что, если нам нужен только текст без каких-либо тегов. Не волнуйтесь, мы обсудим то же самое в этом разделе. Мы будем использовать свойство text. Он печатает только текст из тега. Мы будем использовать приведенный выше пример и удалим из них все теги.
Пример 1. Удаление тегов из содержимого страницы
Python3
Очистка нескольких страниц
Теперь могут возникнуть различные случаи, когда вы можете захотеть получить данные с нескольких страниц с одного и того же веб-сайта или с нескольких разных URL-адресов, а вручную написать код для каждой веб-страницы — трудоемкая и утомительная задача. Кроме того, это противоречит всем основным принципам автоматизации. Ага!
Чтобы решить эту точную проблему, мы увидим два основных метода, которые помогут нам извлекать данные с нескольких веб-страниц:
- Тот же сайт
- Различные URL-адреса веб-сайтов
Пример 1: переход по номерам страниц
номера страниц внизу сайта GeeksforGeeks
Большинство веб-сайтов имеют страницы, помеченные от 1 до N. Это позволяет нам очень просто просматривать эти страницы и извлекать из них данные, поскольку эти страницы имеют схожую структуру. Например:
номера страниц внизу сайта GeeksforGeeks
Здесь мы можем видеть детали страницы в конце URL-адреса. Используя эту информацию, мы можем легко создать цикл for, перебирающий столько страниц, сколько захотим (поместив page / (i) / в строку URL и повторяя «i» до N), и очистить от них все полезные данные. Следующий код прояснит, как очищать данные с помощью цикла For Loop в Python.
Python3
Планы развития
Я использую Grab уже много лет, в том числе и в production сайтах, например в агрегаторе, где можно купить
в Москве и других городах. В 2022 году я начал писать тесты и документацию. Возможно напишу функционал для асинхронных запросов на базе multicurl. Также было бы неплохо допилить urllib-транспорт.
Как можно помочь проекту? Просто используйте его, шлите багрепорты и патчи. Также можете заказывать у меня написание парсеров, граберов, скриптов обработки информации. Регулярно пишу подобные вещи с использованием grab.
Официальный репозиторий проекта: bitbucket.org/lorien/grab Библиотеку можно также поставить с pypi.python.org, но в репозитории обычно код свежее.
UPD: В комментариях озвучивают всяческие альтернативы грабу. Решил резюмировать их списочком кое-что из головы. На самом деле альтернатив этих вагон и маленькая тележка. Думаю, каждый N-ый программист в один прекрасный день решает навелосипедить себе утилитку для сетевых запросов:
Поиск элементов
Теперь мы хотели бы извлечь некоторые полезные данные из содержимого HTML. Объект soup содержит все данные во вложенной структуре, которые могут быть извлечены программно. Веб-сайт, который мы хотим очистить, содержит много текста, поэтому теперь давайте очистим весь этот контент. Во-первых, давайте проверим веб-страницу, которую мы хотим очистить.
Поиск элементов по идентификатору
В приведенном выше примере мы нашли элементы по имени класса, но давайте посмотрим, как найти элементы по идентификатору. Теперь для этой задачи давайте очистим содержимое левой панели страницы. Первый шаг — проверить страницу и увидеть, под какой тег находится левая панель.
На изображении выше показано, что левая панель находится под тегом <div> с id в качестве основного. Теперь давайте возьмем HTML-контент под этим тегом. Теперь давайте посмотрим на большую часть страницы, чтобы получить содержимое левой панели.
Мы видим, что список на левой панели находится под тегом <ul> с классом leftBarList, и наша задача — найти все li под этим ul.
Python3
Вывод:

Извлечение текста из тегов
В приведенных выше примерах вы, должно быть, видели, что при очистке данных теги также очищаются, но что, если нам нужен только текст без каких-либо тегов. Не волнуйтесь, мы обсудим то же самое в этом разделе. Мы будем использовать свойство text. Он печатает только текст из тега. Мы будем использовать приведенный выше пример и удалим из них все теги.
Пример 1. Удаление тегов из содержимого страницы
Python3
importrequests
frombs4 importBeautifulSoup
r =requests.get('https://www.geeksforgeeks.org/python-programming-language/')
soup =BeautifulSoup(r.content, 'html.parser')
s =soup.find('div', class_='entry-content')
lines =s.find_all('p')
forline inlines:
print(line.text)
Вывод:

Пример 2: Удаление тегов из содержимого левой панели
Python3
importrequests
frombs4 importBeautifulSoup
r =requests.get('https://www.geeksforgeeks.org/python-programming-language/')
soup =BeautifulSoup(r.content, 'html.parser')
s =soup.find('div', id='main')
leftbar =s.find('ul', class_='leftBarList')
lines =leftbar.find_all('li')
forline inlines:
print(line.text)
Вывод:

Извлечение ссылок
До сих пор мы видели, как извлекать текст, теперь давайте посмотрим, как извлекать ссылки со страницы.
Пример: Python BeatifulSoup извлекает ссылки
Python3
importrequests
frombs4 importBeautifulSoup
r =requests.get('https://www.geeksforgeeks.org/python-programming-language/')
soup =BeautifulSoup(r.content, 'html.parser')
forlink insoup.find_all('a'):
print(link.get('href'))
Вывод:

Извлечение информации об изображении
При повторном просмотре страницы мы видим, что изображения лежат внутри тега img, а ссылка на это изображение находится внутри атрибута src. См. Изображение ниже —

Пример: Python BeautifulSoup Extract Image
Python3
importrequests
frombs4 importBeautifulSoup
r =requests.get('https://www.geeksforgeeks.org/python-programming-language/')
soup =BeautifulSoup(r.content, 'html.parser')
images_list =[]
images =soup.select('img')
forimage inimages:
src =image.get('src')
alt =image.get('alt')
images_list.append({"src": src, "alt": alt})
forimage inimages_list:
print(image)
Вывод:

Очистка нескольких страниц
Теперь могут возникнуть различные случаи, когда вы можете захотеть получить данные с нескольких страниц с одного и того же веб-сайта или с нескольких разных URL-адресов, а вручную написать код для каждой веб-страницы — трудоемкая и утомительная задача. Кроме того, это противоречит всем основным принципам автоматизации. Ага!
Чтобы решить эту точную проблему, мы увидим два основных метода, которые помогут нам извлекать данные с нескольких веб-страниц:
- Тот же сайт
- Различные URL-адреса веб-сайтов
Пример 1: переход по номерам страниц

номера страниц внизу сайта GeeksforGeeks
Большинство веб-сайтов имеют страницы, помеченные от 1 до N. Это позволяет нам очень просто просматривать эти страницы и извлекать из них данные, поскольку эти страницы имеют схожую структуру. Например:

номера страниц внизу сайта GeeksforGeeks
Здесь мы можем видеть детали страницы в конце URL-адреса. Используя эту информацию, мы можем легко создать цикл for, перебирающий столько страниц, сколько захотим (поместив page / (i) / в строку URL и повторяя «i» до N), и очистить от них все полезные данные. Следующий код прояснит, как очищать данные с помощью цикла For Loop в Python.
Python3
importrequests
frombs4 importBeautifulSoup as bs
URL ='https://www.geeksforgeeks.org/page/1/'
req =requests.get(URL)
soup =bs(req.text, 'html.parser')
titles =soup.find_all('div',attrs ={'class','head'})
print(titles[4].text)
Вывод:
7 самых распространенных потерь времени при разработке программного обеспечения
Теперь, используя приведенный выше код, мы можем получить заголовки всех статей, просто поместив эти строки в цикл.
Python3
importrequests
frombs4 importBeautifulSoup as bs
URL ='https://www.geeksforgeeks.org/page/'
forpage inrange(1, 10):
req =requests.get(URL str(page) '/')
soup =bs(req.text, 'html.parser')
titles =soup.find_all('div', attrs={'class', 'head'})
fori inrange(4, 19):
ifpage > 1:
print(f"{(i-3) page*15}" titles[i].text)
else:
print(f"{i-3}" titles[i].text)
Вывод:

Пример 2: просмотр списка разных URL-адресов
Вышеупомянутый метод абсолютно замечателен, но что, если вам нужно очистить разные страницы, и вы не знаете их номера? Вам нужно будет очистить эти разные URL-адреса один за другим и вручную написать сценарий для каждой такой веб-страницы.
Вместо этого вы можете просто составить список этих URL-адресов и просмотреть их в цикле. Просто перебирая элементы в списке, то есть URL-адреса, мы сможем извлекать заголовки этих страниц без необходимости писать код для каждой страницы. Вот пример кода, как это можно сделать.
Python3
importrequests
frombs4 importBeautifulSoup as bs
URL =['https://www.geeksforgeeks.org','https://www.geeksforgeeks.org/page/10/']
forurl inrange(,2):
req =requests.get(URL[url])
soup =bs(req.text, 'html.parser')
titles =soup.find_all('div',attrs={'class','head'})
fori inrange(4, 19):
ifurl 1> 1:
print(f"{(i - 3) url * 15}" titles[i].text)
else:
print(f"{i - 3}" titles[i].text)
Вывод:

Для получения дополнительной информации см. Наше руководство по Python BeautifulSoup.
Сохранение данных в csv
Сначала мы создадим список словарей с парами ключ-значение, которые мы хотим добавить в файл CSV. Затем мы будем использовать модуль csv для записи вывода в файл CSV. См. Пример ниже для лучшего понимания.
Пример: сохранение Python BeautifulSoup в CSV
Python3
importrequests
frombs4 importBeautifulSoup as bs
importcsv
URL ='https://www.geeksforgeeks.org/page/'
soup =bs(req.text, 'html.parser')
titles =soup.find_all('div', attrs={'class', 'head'})
titles_list =[]
count =1
fortitle intitles:
d ={}
d['Title Number'] =f'Title {count}'
d['Title Name'] =title.text
count =1
titles_list.append(d)
filename ='titles.csv'
with open(filename, 'w', newline='') as f:
w =csv.DictWriter(f,['Title Number','Title Name'])
w.writeheader()
w.writerows(titles_list)
Вывод:

Поиск элементов по классу
На изображении выше мы видим, что все содержимое страницы находится под блоком div с классом entry-content. Мы будем использовать класс find. Этот класс найдет данный тег с данным атрибутом. В нашем случае он найдет весь div, имеющий class как entry-content.
Мы видим, что содержимое страницы находится под тегом <p>. Теперь нам нужно найти все теги p, присутствующие в этом классе. Мы можем использовать класс find_all в BeautifulSoup.
Python3
Проверка веб-сайта
Прежде чем извлекать какую-либо информацию из HTML страницы, мы должны понять структуру страницы. Это нужно сделать для того, чтобы выделить нужные данные со всей страницы. Мы можем сделать это, щелкнув правой кнопкой мыши страницу, которую мы хотим очистить, и выбрав элемент проверки.
После нажатия кнопки проверки откроются инструменты разработчика браузера. Теперь почти все браузеры поставляются с установленными инструментами разработчика, и в этом руководстве мы будем использовать Chrome.
Инструменты разработчика позволяют увидеть объектную модель документа (DOM) сайта. Если вы не знаете о DOM, не беспокойтесь, просто рассмотрите отображаемый текст как HTML-структуру страницы.
Работа с cookies
По-умолчанию, Grab сохраняет полученные cookies и отсылает их в следующем запросе. Вы получаете эмуляцию пользовательских сессий из коробки. Если вам это не нужно, отключите опцию `reuse_cookies`. Вы можете задать cookies вручную опцией `cookies`, она должна содержать словарик, обработка которого аналогична обработке данных, переданных в `post` опции.
>>> g.setup(cookies={'secureid': '234287a68s7df8asd6f'})
Вы можете указать файл, который следует использовать как хранилище cookies, опцией `cookiefile`. Это позволит вам сохранять cookies между запусками программы.
В любой момент вы можете записать cookies Grab объекта в файл методом `dump_cookies` или загрузить из файла методом `load_cookies`. Чтобы очистить cookies Grab объекта используйте метод `clear_cookies`.
Работа с dom-деревом (grab.ext.lxml расширение)
Подходим к самому интересному. Благодаря замечательной библиотеке lxml Grab предоставляет вам возможность работать с xpath-выражениями для поиска данных. Если очень кратко: через аттрибут `tree` вам доступно DOM-дерево с ElementTree интерфейсом. Дерево строится с помощью парсера библиотеки lxml. Работать с DOM-деревом можно используя два языка запросов: xpath и css.
Методы работы с xpath:
Если элемент не был найден, то функции `xpath`, `xpath_text` и `xpath_number` сгенеририруют DataNotFound исключение.
Функции `css`, `css_list`, `css_text` и `css_number` работают аналогично, за одним исключением, аргументом должен быть не xpath-путь, а css-селектор.
Работа с ответом
Допустим, вы сделали сетевой запрос с помощью Grab. Что дальше? Методы `go` и `request` вернут вам объект Response, который также доступен через аттрибут `response` объекта Grab. Вас могут заинтересовать следующие аттрибуты и методы объекта Response: code, body, headers, url, cookies, charset.
Grab объект имеет метод `response_unicode_body`, который возвращает тело ответа, преобразованное в unicode, учтите, что HTML entities типа “&” не преобразовывается в уникодовые аналоги.
Response объект последнего запроса всегда хранится в аттрибуте `response` Grab объекта.
Работа с текстом ответа (grab.ext.text расширение)
Метод `search` позволяет установить присутствует ли заданная строка в теле ответа, метод `search_rex` принимает в качестве параметра объект регулярного выражения. Методы `assert_substring` и `assert_rex` генерируют DataNotFound исключение, если аргумент не был найден.
Разбор html
После получения HTML-кода страницы давайте посмотрим, как проанализировать этот необработанный HTML-код и получить полезную информацию. Прежде всего, мы создадим объект BeautifulSoup, указав парсер, который мы хотим использовать.
Примечание. Библиотека BeautifulSoup построена на основе библиотек синтаксического анализа HTML, таких как html5lib, lxml, html.parser и т. Д. Таким образом, объект BeautifulSoup и указанная библиотека синтаксического анализатора могут быть созданы одновременно.
Пример: Python BeautifulSoup анализирует HTML
Python3
Режим молотка (hammer-mode)
Этот режим включен по-умолчанию. Для каждого запроса у Grab есть таймаут. В режиме молотка в случае таймаута Grab не генерирует сразу исключение, а пытается ещё несколько раз сделать запрос с возростающими таймаутами. Этот режим позволяет значительно увеличить стабильность программы т.к. микро-паузы в работе сайтов или разрывы в канале встречаются сплошь и рядом.
Для включения режима испльзуйте опцию `hammer_mode`, для настройки количества и длины таймаутов используйте опцию `hammer_timeouts`, в которую должен быть передан список числовых пар: первое число это таймаут на соединение с сокетом сервера, второе число — таймаут на всё время операции, включая получение ответа.
Сохранение данных в csv
Сначала мы создадим список словарей с парами ключ-значение, которые мы хотим добавить в файл CSV. Затем мы будем использовать модуль csv для записи вывода в файл CSV. См. Пример ниже для лучшего понимания.
Пример: сохранение Python BeautifulSoup в CSV
Python3
Сохранение результата
Саму страничку мы как-то получили. Теперь задача вытащить оттуда все данные. Для начала опишем модель того, что нам нужно в файле items.py:
То есть требуемый csv файл будет состоять из строк такой вот структуры. Проще всего раз получить пример страницы и подобрать соответствующие XPath для данных в response:
Модифицируем метод parse, чтобы он возвращал именно HabrItem. Для упрощения воспользуемся встроенным классом Selector, хотя не больно-то он и помогает – страдать от XPath всё равно придётся:
Работа с XPath местами неочевидна и явно выходит за рамки этого материала. В итоге в логах можно видеть что же именно скачалось. Но нам-то это надо видеть в файле, так что посмотрим на pipelines.py. Используется концепция пайплайнов unix – данные передаются из одного объекта в другой, проходя какую-нибудь обработку.
Зачем так сложно? Почему нельзя сразу в методе parse сохранять результаты? Всё из-за гибкости – здесь нужно разделять способ получения данных от способа обработки, т.к. первый будет переписываться из-за адаптации к структуре сайта. Разработчики любят менять имена стилей, убирать html-элементы, так что данные могут оказаться совсем в другом месте, а то и вовсе подтягиваться ajax-запросами. Так что код, представленный здесь, скорее всего не заработает сразу, а потребует небольшого допиливания.
После подключения HabrPipeline в settings.py и запуска scrapy crawl HabrSpider -o habr.json -t json получаем файл habr.json, в котором содержатся элементы с главной Хабра.
Транспорты
По-умолчанию, Grab использует pycurl для всех сетевых операций. Эта фунциональность реализована тоже в виде расшерения и можно подключить другое транспорт-расширение, например, для запросов через urllib2 библиотеку. Есть только одна проблема, это расширение нужно предварительно написать 🙂
Работы по urllib2 расширению ведутся, но весьма неспешно — меня на 100% устраивает pycurl. Я думаю, pycurl и urllib2 расширения по-возможностям будут аналогичны, за исключением того, что urllib2 не умеет работать с SOCKS-проксями. Все примеры, приведённые в данной статье используют pycurl-транспорт, который включен по-умолчанию.
>>> g = Grab()
>>> g.curl
<pycurl.Curl object at 0x9d4ba04>
>>> g.extensions
[<grab.ext.pycurl.Extension object at 0xb749056c>, <grab.ext.lxml.Extension object at 0xb749046c>, <grab.ext.lxml_form.Extension object at 0xb6de136c>, <grab.ext.django.Extension object at 0xb6a7e0ac>]
Установка
Чтобы установить Beautifulsoup в Windows, Linux или любой другой операционной системе, потребуется пакет pip. Чтобы узнать, как установить pip в вашей операционной системе, посмотрите — Установка PIP — Windows || Linux. Теперь запустите следующую команду в терминале.
pip install beautifulsoup4
Установка и создание проекта
Для начала установим scrapy. Он тянет довольно много сторонних зависимостей:
После этого создадим проект:
И ниже он предлагает создать первого паука:
В итоге в каталоге spiders появился первый алгоритм паука с вот таким содержимым:
У каждого такого паука есть имя, по которому мы будем его запускать, список доменов, на которые можно переходить и стартовый url.
Формы (grab.ext.lxml_form расширение)
Когда я реализовал функциональность по автоматическому заполнению форм я был очень рад. Порадуйтесь и вы! Итак, есть методы `set_input` — заполняет поле с указанным именем, `set_input_by_id` — по значению аттрибута id, и `set_input_by_number` — просто по номеру.
Эти методы работают с формой, которую можно задать руками, но обычно Grab сам угадывает правильно, с какой формой нужно работать. Если форма одна — всё понятно, а если несколько? Grab возьмёт ту форму, в которой больше всего полей. Чтобы задать форму вручную используйте метод `choose_form`.
Методом `submit` можно отправить заполненную форму. Grab сам построит POST/GET запрос для полей, которые мы не заполнили явно (например hidden поля), вычислит action формы и метод запроса. Есть также метод `form_fields` который вернёт в словарике все поля и значения формы.
Шаг 1. установка библиотек
Прежде всего, нам нужно установить нужные библиотеки, а именно:
- BeautifulSoup4
- Requests
- pandas
- lxml
Для установки библиотеки вы можете использовать pip install [имя библиотеки] или conda install [имя библиотеки], если у вас Anaconda Prompt.
«Requests» — это наша следующая библиотека для установки. Ее задача — запрос разрешения у сервера, если мы хотим получить данные с его веб-сайта. Затем нужно установить pandas для создания фрейма данных и lxml, чтобы изменить HTML на формат, удобный для Python.
Шаг 10. использование цикла for для создания списка строк
Чтобы сделать список из всех строк, необходимо создать цикл for.
Шаг 2. импортирование библиотек
После установки библиотек давайте откроем вашу любимую среду разработки. Мы предлагаем использовать Spyder 4.2.5. Позже на некоторых этапах работы мы столкнемся с большими объемами выводимых данных и тогда Spyder будет удобнее в использовании чем Jupyter Notebook.
Итак, Spyder открыт и мы можем импортировать необходимую библиотеку:
# Import libraryfrom bs4 import BeautifulSoupimport requests
Шаг 3. выбор страницы
В этом проекте мы будем использовать webscraper.io. Поскольку данный веб-сайт создан на HTML, код легче и понятнее даже новичкам. Мы выбрали эту страницу для парсинга данных:
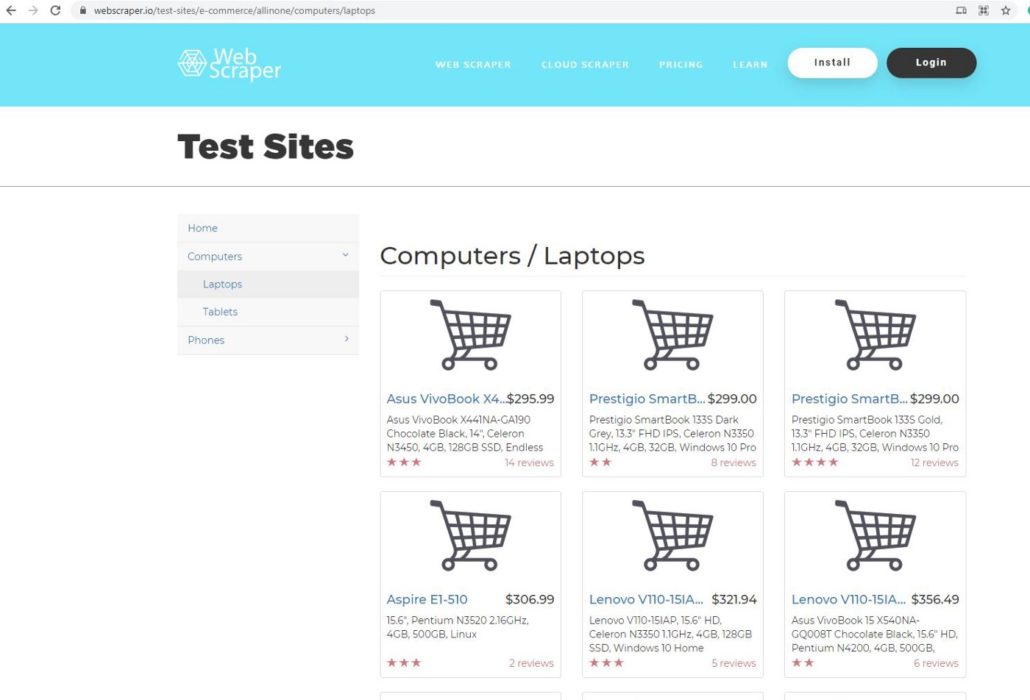
Она является прототипом веб-сайта онлайн магазина. Мы будем парсить данные о компьютерах и ноутбуках, такие как название продукта, цена, описание и отзывы.
Шаг 4. запрос на разрешение
После выбора страницы мы копируем ее URL-адрес и используем request, чтобы запросить разрешение у сервера на получение данных с их сайта.
Шаг 5. просмотр кода элемента
Для парсинга сайтов на Python мы рекомендуем использовать Google Chrome, он очень удобен и прост в использовании. Давайте узнаем, как с помощью Chrome просмотреть код веб-страницы. Сначала нужно щелкнуть правой кнопкой мыши страницу, которую вы хотите проверить, далее нажать Просмотреть код и вы увидите это:
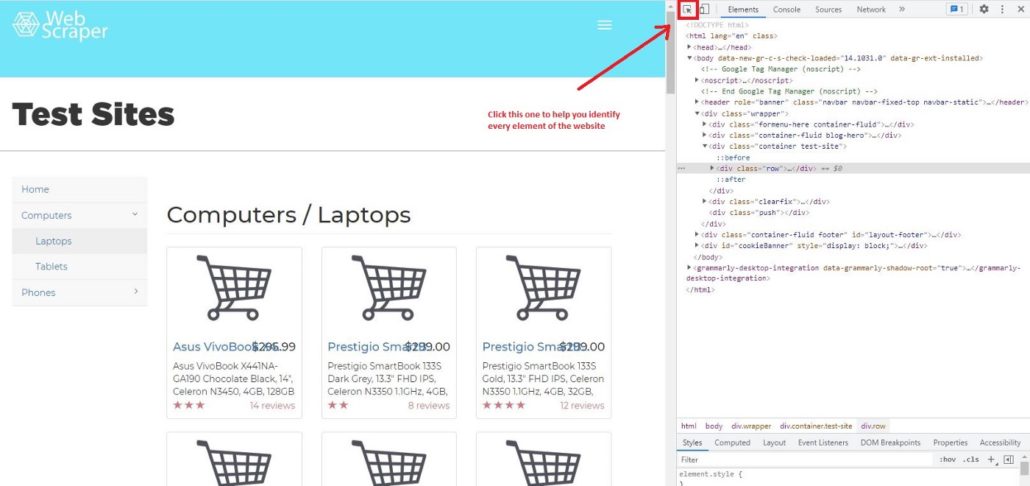
Затем щелкните Выбрать элемент на странице для проверки и вы заметите, что при перемещении курсора к каждому элементу страницы, меню элементов показывает его код.
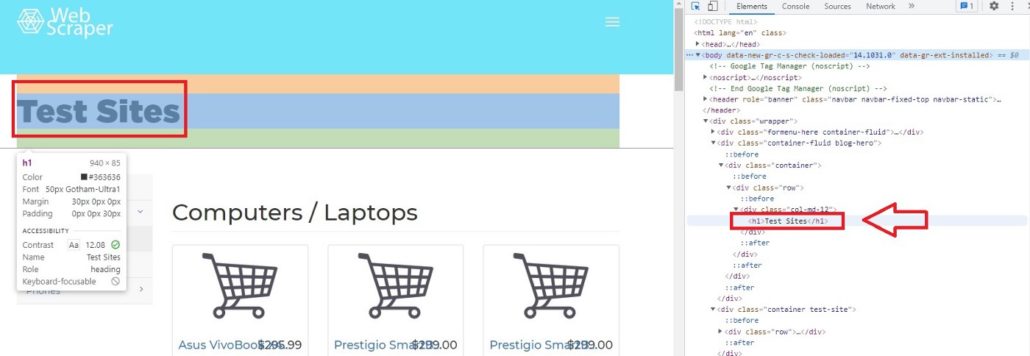
Например, если мы переместим курсор на Test Sites, элемент покажет, что Test Sites находится в теге h1. В Python, если вы хотите просмотреть код элементов сайта, можно вызывать теги. Характерной чертой тегов является то, что они всегда имеют < в качестве префикса и часто имеют фиолетовый цвет.
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
Шаг 6. доступ к тегам
Если мы, к примеру, хотим получить доступ к элементу h1 с помощью Python, мы можем просто ввести:
# Access h1 tagsoup.h1
Результат будет:
soup.h1Out[11]: <h1>Test Sites</h1>
Вы можете получить доступ не только к однострочным тегам, но и к тегам класса, например:
# Access header tagsoup.header#Access div tag soup.div
Не забудьте перед этим определить soup, поскольку важно преобразовать HTML в удобный для Python формат.
Вы можете получить доступ к определенному из вложенных тегов. Вложенные теги означают теги внутри тегов. Например, тег <p> находится внутри другого тега <header>. Но когда вы получаете доступ к определенному тегу из <header>
# Access string from nested tagssoup.header.p
Результат:
soup.header.pOut[10]: <p>Web Scraper</p>
Вы также можете получить доступ к строке вложенных тегов. Нужно просто добавить в код string.
# Access string from nested tagssoup.header.psoup.header.p.string
Результат:
soup.header.psoup.header.p.stringOut[12]: ‘Web Scraper’
Следующий этап парсинга сайтов на Python — это получение доступа к атрибутам тегов. Для этого мы можем использовать функциональную возможность BeautifulSoup attrs. Как результат применения attrs мы получим словарь.
# Access ‘a’ tag in <header>
a_start = soup.header.a
a_start#
Access only the attributes using attrs
a_start.attrsРезультат:
Out[16]:{‘data-toggle’: ‘collapse-side’,‘data-target’: ‘.side-collapse’,‘data-target-2’: ‘.side-collapse-container’}
Мы можем получить доступ к определенному атрибуту. Учтите, что Python рассматривает атрибут как словарь, поэтому data-toggle, data-target и data-target-2 являются ключом. Вот пример получение доступа к ‘data-target:
a_start[‘data-target’]
Результат:
a_start[‘data-target’]Out[17]: ‘.side-collapse’
Мы также можем добавить новый атрибут. Имейте в виду, что изменения влияют только на веб-сайт локально, а не на веб-сайт в мировом масштабе.
a_start[‘new-attribute’] = ‘This is the new attribute’a_start.attrsa_start
Результат:
Шаг 7. доступ к конкретным атрибутам тегов
Мы узнали, что в теге может быть больше чем один вложенный тег. Например, если мы запустим soup.header.div, <div> будет иметь много вложенных тегов. Учтите, что мы вызываем только <div> внутри <header >, поэтому другой тег внутри <header> не будет показан.
Результат:
Шаг 8. использование фильтра
При необходимости мы можем найти несколько тегов:
# Using filter to find multiple tagssoup.find_all([‘h4’, ‘a’, ‘p’])soup.find_all([‘header’, ‘div’])soup.find_all(id = True) # class and id are special attribute so it can be written like thissoup.find_all(class_= True)
Поскольку class и id являются специальными атрибутами, поэтому можно писать class_ и id вместо ‘class’ или ‘id’.
Использование фильтра поможет нам получить необходимые данные с веб-сайта. В нашем случае это название, цена, отзывы и описания. Итак, сначала определим переменные.
# Filter by name name = soup.find_all(‘a’, class_=’title’) # Filter by priceprice = soup.find_all(‘h4’, class_ = ‘pull-right price’)# Filter by reviews reviews = soup.find_all(‘p’, class_ = ‘pull-right’)# Filter by description description = soup.find_all(‘p’, class_ =’description’)
Фильтр по названию:
Заключение
Полный код проекта находится в репозитории на github. На этом же простейший паук готов, но это далеко не все возможности фреймворка. Я боюсь их даже перечислять, так что за подробностями отправляю на страницу документации.