Что такое аутентификация?
На процессах аутентификации и авторизации основано разделения прав доступа, без которого не обходится ни одно более или менее серьезное приложение. Поэтому понимать, как они происходили раньше и происходят теперь, очень важно, но, прежде чем углубиться в описание технологии, давайте разберемся с ключевыми терминами.
Идентификация — процесс определения, что за человек перед нами. Аутентификация — процесс подтверждения, что этот человек именно тот, за кого себя выдает. Авторизация — процесс принятия решения о том, что именно этой аутентифицированной персоне разрешается делать.
В ходе аутентификации мы удостоверяемся, что человек, который к нам пришел, обладает доказательствами, подтверждающими личность. В этой статье речь в основном пойдет как раз об аутентификации.
1 Время восстановления/энтропия входных параметров
Авторизация принимает решение о разграничении доступа на основе множества входных параметров. Если таковых будет слишком много, либо мерность множеств окажется слишком большой, то авторизация будет терять слишком много ресурсов на выполнение ненужных операций. Это как сортировать данные пузырьком и qsort. Не следует выполнять ненужные операции.
Если у вашей системы есть на входе A,B,C,D,E,F — факты о пользователе, то если вы будете объединять все в одно, то получите A * B * C * D * E * F комбинаций, которые невозможно эффективно кешировать. По возможности следует найти такую комбинацию входных, что бы у вас было A * B * C и D * E * F комбинаций, а еще лучше A * B, C * D, E * F, которые вы уже легко сможете вычислять и кешировать.
Эта характеристика очень важна так же для построения системы правил, которые будут предоставлять пользователям доступы.
10 О кешировании данных
Основной проблемой при работе авторизации является точка в которой необходимо кешировать результаты, что бы работало быстрее все, да еще желательно так, что бы нагрузка на ЦПУ не была высокой. Вы можете поместить все ваши данные в память и спокойно их читать, но это дорогое решение и не все готовы будут себе его позволить, особенно если требуется всего лишь пара ТБ ОЗУ.
Правильным решением было бы найти такие места, которые бы позволяли с минимальными затратами по памяти давать максимум быстродействия.
Предлагаю решить такую задачу на примере ролей пользователя и некоего микросервиса, которому нужно проверять наличие роли у пользователя. Разумеется в данном случае можно сделать карту (Пользователь, Роль) -> Boolean. Проблема в том, что все равно придется на каждую пару делать запрос на удаленный сервис.
Даже если вам данные будут предоставлять за 0,1 мс, то ваш код будет работать все равно медленно. Очевидным решением будет кешировать сразу роли пользователя! В итоге у нас будет кеш Пользователь -> Роль[]. При таком подходе на какое-то время микросервис сможет обрабатывать запросы от пользователя без необходимости нагружать другие микросервисы.
Разумеется читатель спросит, а что если ролей у пользователя десятки тысяч? Ваш микросервис всегда работает с ограниченным количеством ролей, которые он проверяет, соответственно вы всегда можете либо захардкодить список, либо найти все аннотации, собрать все используемые роли и фильтровать только их.
Полагаю, что ход мыслей, которому стоит следовать, стал понятен.
5 Роль
Множество разрешений, по сути под словом роль всегда подразумевается множество разрешений.
Следует отметить, что в системе может не быть ролей и напрямую задаваться набор разрешений для каждого пользователя в отдельности. Так же в системе могут отсутствовать разрешения (речь про хранение их в виде записей БД), но быть роли, при этом такие роли будут называться статичными, а если в системе существуют разрешения, тогда роли называются динамическими, так как можно в любой момент поменять, создать или удалить любую роль так, что система все равно продолжит функционировать.
Ролевые модели позволяют как выполнять вертикальное, так и горизонтальное разграничение доступа (описание ниже). Из типа разграничения доступа следует, что сами роли делятся на типы:
Но отсюда следует вопрос, если у пользователя есть глобальная роль и локальная, то как определить его эффективные разрешения? Поэтому авторизация должна быть в виде одной из форм:
Подробное описание использования типа ролей и формы авторизации ниже.
Роль имеет следующие связи:
Следует отметить, что реализация статичных ролей требует меньше вычислительных ресурсов (при определении эффективных разрешений пользователя будет на один джойн меньше), но вносить изменения в такую систему можно только релизным циклом, однако при большом числе ролей гораздо выгоднее использовать разрешения, так как чаще всего микросервису нужно строго ограниченное их число, а ролей с разрешением может быть бесконечное число. Для больших проектов, стоит задуматься о том, что бы работать только с динамическими ролями.
6 Группа
Используя группы можно объединить множество ресурсов, в том числе расположенных в разных сервисах в одно целое, и управлять доступом к ним используя одну точку. Это позволяет гораздо проще и быстрее реализовывать предоставление доступа пользователя к большим массивам информации, не требуя избыточных данных в виде записи на каждый доступ к каждому ресурсу по отдельности вручную или автоматически. По сути вы решаете задачу предоставления доступа к N ресурсам создавая 1 запись.
Группы используются исключительно для горизонтального разграничения доступа (описание ниже). Даже если вы будете использовать группы для доступа к сервисам, то это все равно горизонтальное разграничение доступа, потому что сервис — это совокупность ресурсов.
Группа имеет следующие связи:
9 Конъюнктивная/дизъюнктивная форма авторизации
Из-за того, что у теперь у нас существуют два варианта наборов разрешений пользователя, то можно выделить два варианта, как объединить все вместе:
Одним из важных преимуществ конъюнктивной формы является жесткий контроль за всеми операциями, которые может выполнять пользователь, а именно — без глобального разрешения пользователь не сможет получить доступ в следствие ошибки на месте. Так же реализация в виде программного продукта горазо проще, так как достаточно сделать последовательность проверок, каждая из которых либо успешна, либо бросает исключение.
Дизъюнктивная форма позволяет гораздо проще делать супер-админов и контролировать их численность, однако на уровне отдельных сервисов потребует написания своих алгортмов авторизации, которые в начале получит все разрешения пользователя, а уже потом либо успешно пройдет, либо бросит исключение.
Рекомендуется всегда использовать только конъюнктивную форму авторизации в виду ее большей гибкости и возможности снизить вероятность появления инцидентов по утечке данных. Так же именно конъюнктивная форма авторизации имеет большую устойчивость к ДДОС атакам в виду использования меньшего объема ресурсов.
Ее проще реализовать и использовать, отлаживать. Разумеется можно и дизъюнктивную форму натравить на анализ аннотаций метода и поиск соответствующих сервисов, но запросы вы отправлять будете скорее всего синхронно, один за другим, если же будете делать асинхронные вызовы, то много ресурсов будет уходить в пустоту, оно вам надо?
2 Логистика
Огромная логистическая компания требует разграничить доступы для супервизоров и продавцов да еще с учетом региона. Работа такова, что продавец может выставить заявку на получение товара, а супервизор уже решает кому и сколько достанется. Соответственно продавец может видеть свой магазин и все товары в нем, а так же созданные им заявки, статус их обработки.
Для реализации такого функционала нам потребуется реестр регионов и магазинов в качестве отдельного микросервиса, назовем его С1. Заявки и историю будем хранить на С2. Авторизация — А.Далее при обращении продавца для получения списка его магазинов (а у него может быть их несколько)
, С1 вернет только те, в которых у него есть меппинг (Пользователь, Магазин), так как ни в какие регионы он не добавлен и для продавца регионы всегда пустое множество. Разумеется при условии, что у пользователя есть разрешение просматривать список магазинов — посредством микросервиса А.
Работа супервизора будет выглядеть немного иначе, вместо регистрации супервизора на каждый магазин региона, мы сделаем меппинги (Пользователь, Регион) и (Регион, Магазин) в этом случае для супервизора у нас всегда будет список актуальных магазинов с которыми он работает.
4 Команда и ее проекты
Если у вас большая команда, и много проектов, и такая команда у вас не одна, то координировать работу их будет той еще задачей. Особенно если таких команд у вас тысячи. Каждому разработчику вы доступы не пропишите, а если у вас человек еще и в нескольких командах работает, то разграничивать доступ станет еще сложнее.
Такую проблему проще всего решить при помощи групп.Группа будет объединять все необходимые проекты в одно целое. При добавлении участника в команду, добавляем меппинг (Пользователь, Группа, Роль).
Допустим, что Вася — разработчик и ему нужно вызвать метод develop на микросервисе для выполнения своих обязанностей. Этот метод потребует у Васи роли в проекте — Разработчик.Как мы уже договаривались — регистрация пользователя в каждый проект для нас недопустима.
Поэтому микросервис проектов обратится в микросервис групп, что бы получить список групп, в которых Вася — Разработчик. Получив список этих групп можно легко проверить уже в БД микросервиса проектов — есть ли у проекта какая-нибудь из полученных групп и на основании этого предоставлять или запрещать ему доступ.
2 Архитектура решения
Для решения поставленной задачи нам необходимы следующие микросервисы:
- Ролевая модель для глобальной авторизации запросов
- Чайный сервис для предоставления возможности пить чай и получать статистику по выпитому
- Кракен — гейт с проверкой доступа к точке, все остальные проверки совершит чайный сервис
Графически это будет выглядеть так:
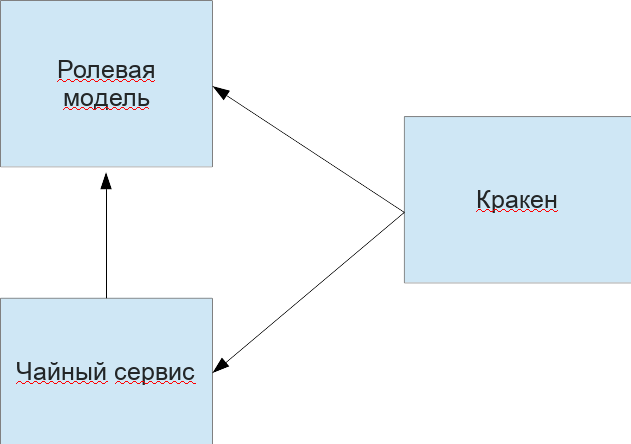
В качестве БД будем использовать PostgreSQL.Предусмотрим следующие обязательные для решения задачи роли:
- Сотрудник — для возможности пить чай;
- Удаленный сотрудник — для доступа к микросервису кракена (так как сотрудники в офисе не должны иметь возможности пить чай через точки распрастранения чая);
- Кракен — учетная запись микросервиса, что бы была возможность обращаться к API чайного сервиса;
- Авторизационная учетная запись — для предоставления доступа микросервисов к ролевой модели.
Shared library vs sidecar
Выбранный подход не избавил нас от такой проблемы: поначалу функционал авторизации распространялся в виде библиотеки. Любое добавление нового функционала или изменение существующего функционала ролевой модели (а в момент ее создания и начальных этапов развития это происходило довольно часто) означало обновление всех сервисов, которых это изменение касается.
Для решения этой проблемы мы решили применить архитектурный шаблон «Ambassador» — вынести функционал, который касается авторизации, в отдельный Sidecar и назвали его Security proxy.
Доменный сервис деплоится вместе с Security proxy в одном Pod-е в Kubernetes. Среда настраивается так, чтобы исключить возможность запросов к доменным сервисам не через Security proxy. Сам Security proxy ничего не знает о логике доменного сервиса, ему лишь известно API, выставленное доменным сервисом наружу, он выступает в роли амбассадора.
Непосредственно сервис декларативно размечает поля директивами и фокусируется только на бизнес-логике приложения. В случае необходимости изменения логики работы авторизации можно независимо от сервисов массово обновить Security proxy, не нарушая работу продуктовой логики и не пересобирая продуктовые сервисы. Это позволяет использовать один и тот же механизм авторизации для сервисов, использующих различные технологии.
Token authentication
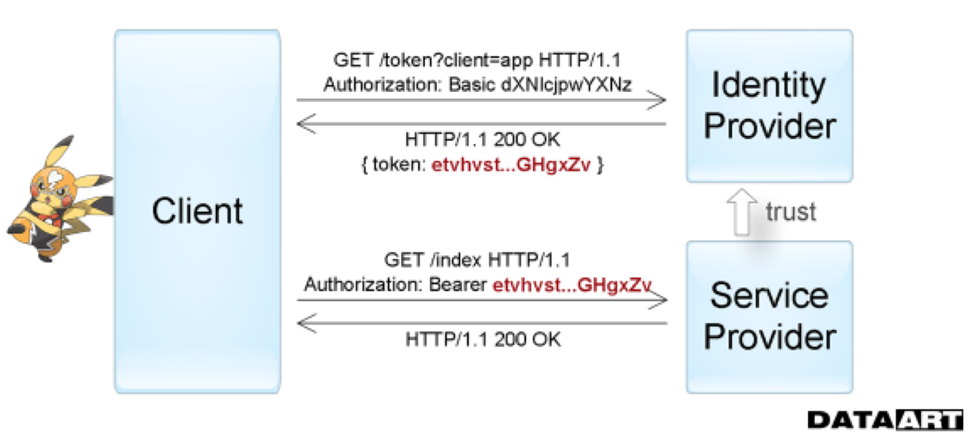
Следующее поколение способов аутентификации представляет Token Based Authentication, который обычно применяется при построении систем Single sign-on (SSO). При его использовании запрашиваемый сервис делегирует функцию проверки достоверности сведений о пользователе другому сервису. Т. е. провайдер услуг доверяет выдачу необходимых для доступа токенов собственно токен-провайдеру (Identity provider).
Это то, что мы видим, например, входя в приложения через аккаунты в социальных сетях. Вне IT самой простой аналогией этого процесса можно назвать использование общегражданского паспорта. Официальный документ как раз является выданным вам токеном — все государственные службы по умолчанию доверяет отделу полиции, который его вручил, и считает паспорт достаточным для вашей аутентификации на протяжении всего срока действии при сохранении его целостности.
На схеме хорошо видно, как и в какой последовательности приложения обмениваются информацией при использовании аутентификацией по токенам.
На следующей схеме дополнительно отражены те этапы взаимодействия, в которых пользователь принимает непосредственное участие. Этот момент и является недостатком подобной схемы — нам всегда нужен пользователь, чтобы получить доступ к ресурсу.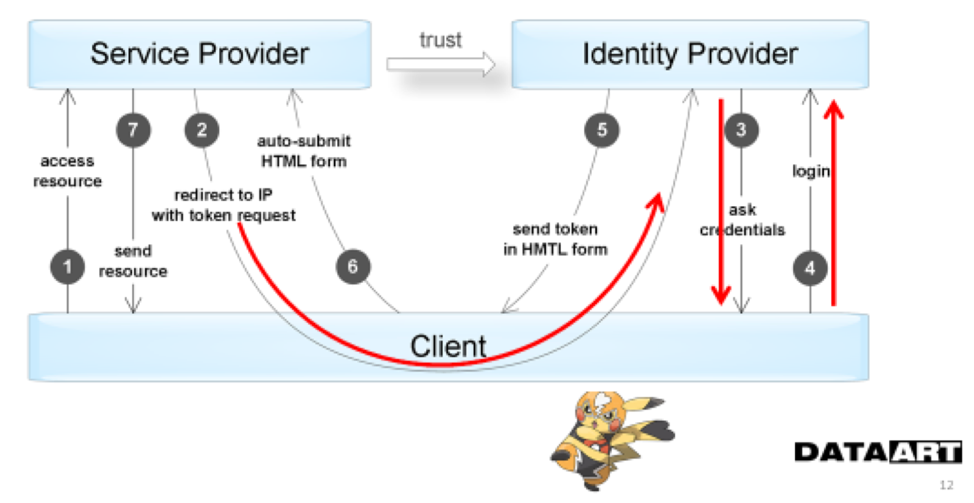
Варианты решений
Разумеется, начали с классического, проверенного подхода — WSDL. Но уже на тот момент технология считалась устаревшей и не очень дружила с .NET Core в части создания сервера. А на тот момент .NET Core стал нашим основным стеком.
Другим вариантом для нас было использование технологии OpenAPI. Это решение оказалось значительно лучше и мы его какое-то время использовали. Но такой подход не прошел проверку временем, т.к. реализации OpenAPI в разных стеках были не совместимы между собой.
Мы даже думали отказаться от НТТР API совсем и использовать для взаимодействия только брокер очередей. Пытались воспользоваться внутренним протоколом обмена данных между сервисами для внешних потребителей. Это обычный JSON-документ, вполне очевидно, содержащий имена операций, их параметры и информацию о типах.
Сделали описание сервисов в виде документа в формате JSON Schema. В результате стало возможным взаимодействовать с сервисами по внутреннему протоколу на разных платформах. Но, поразмыслив, поняли, что сломаем еще много копий на этом подходе. А также, прикинув, как придется поддерживать это решение и распространять на потенциальные другие платформы, делать то же самое на других языках программирования, приняв во внимание отсутствие какого-либо стандарта и «прекрасную» возможность получить проблемы во всей внутренней шине данных, поняли, что это тупик.
Мы стали подумывать о каком-то гибридном варианте, при котором потребители сами смогут определять, какие данные им нужны от поставщиков (Consumer Driven Contracts). Присматривались к таким технологиям как oData, но примерно в это время на сцене появилась технология GraphQL.
Если быть точным, то сама технология появилась в 2022 году, а в тот момент, как говорят наши архитекторы, она уже зеленела на техрадаре. Наши исследования и эксперименты показали, что технология предоставляет решения к обозначенным выше проблемам «из коробки», хотя и была довольно сыровата на тот момент.
В итоге на начальных этапах текущего проекта и создания нашей микросервисной платформы было принято решение, что, GraphQL будет обязательным стандартом к доменным сервисам.
Не будем в деталях рассказывать что такое GraphQL, на просторах интернета много хороших статей на эту тему. Скажем лишь, чтоGraphQL — стандарт, который описывает взаимодействие между поставщиками и потребителями контрактов.
Реализаций у этого стандарта может быть несколько. На тот момент, когда мы начинали создавать платформу, основной стек разработки на бэке был .Net (сегодня добавилась Java) и в качестве основной имплементации была выбрана библиотека graphql-dotnet.
Контракты
Кроме того, возникала проблема обмена знаниями о контрактах сервиса с потребителями. Отправлять клиента на какую-то wiki-страницу во внутренней сети с неактуальной документацией случалось, наверное, каждому разработчику. Если нет, значит, возможно, доводилось быть в еще более неприятной ситуации.
Так что очевидным требованием была автоматическая, структурированная документация. Разработчики не любят писать документацию по разным причинам: кто-то не видит в этом смысла, руководствуясь тем, что такая документация всегда находится в неактуальном состоянии, а кто-то просто не успевает в пылу дедлайнов отражать изменения на странице в wiki.
У нас давно практикуется документация кода xml-комментариями. Поэтому, предоставив разработчикам такой инструмент, мы получали описание API прямо в коде, которое менялось одновременно с самим кодом и позволяло иметь максимально актуальную информацию о сервисах и их контрактах.
Особенности конкретных реализаций graphql
Довольно нетривиально оказалось «подружить» GraphQL с Security Proxy, который инкапсулирует в себе логику авторизации.
При проектировании взаимодействия между самим сервисом и Security Proxy встал вопрос, как Security Proxy будет узнавать о том, к каким полям и методам можно предоставлять соответствующий доступ. О самих полях схемы можно было узнать при помощи специального стандартного запроса — интроспекции, а вот стандартного механизма передачи знаний о том, какой специфический доступ к ним разрешить, не существовало.
В качестве решения этой проблемы было предложено размечать поля схемы соответствующей метаинформацией, по которой Security Proxy будет понимать, разрешен ли доступ к этому полю для текущего запроса или нет. В спецификации GraphQL есть потенциальная возможность сделать это при помощи директив – специальных атрибутов, которыми может быть размечена схема.
В самом стандарте предопределены три директивы: серверная deprecated и клиентские skip и include. Можно было разметить схему дополнительными кастомными директивами, но стандарт не представлял никаких четких указаний по передаче этих директив в интроспекции.
Нам частично пришлось реализовывать это самостоятельно, параллельно убеждая владельцев стандарта легализовать такие изменения. Рабочая группа стандарта ждала, пока кто-нибудь реализует возможность передачи кастомных директив в интроспекции. А разработчики библиотеки graphql-dotnet, которую мы активно используем, ждали, пока это будет явно указано в стандарте.
Долгое время в качестве решения мы использовали форк от официального репозитория, в котором были сделаны необходимые изменения. А именно, были добавлены дополнительные типы, описывающие директивы (__AppliedDirective) и тип ее аргументов (__DirectiveArgument).
Поддерживать форк было достаточно проблематично, поскольку репозиторий активно развивается и новые версии выходят достаточно часто, причем с функционалом, который нам очень хотелось бы видеть в своем проекте. Поэтому удалось найти компромисс с ментейнерами библиотеки graphql-dotnet и добавить глобальный флаг-переключатель «экспериментального» функционала.
Позже аналогичное решение, основанное на нашем примере, было перенесено и в библиотеку GraphQL Java. В спецификации самого стандарта эти изменения по-прежнему не до конца легализованы и существуют в виде запроса на изменения, который вызывает активные обсуждения группы владельцев стандарта.
Ошибка в выборе формата
Поначалу мы записывали названия ролей и операций в GT текстом. GT в свою очередь помещался в Header запроса. Очень быстро получили такую проблему: Header увеличивался в размерах и стал превышать дефолтное значение нашего маршрутизатора, которое составляло 4Кб.
Пришлось увеличивать размер заголовка в параметрах маршрутизатора и срочно делать бинарную сериализацию. При использовании бинарной сериализации токены стали значительно меньше, но даже при таком подходе они разрастаются по мере увеличения количества сервисов и доступных операций.
Приходится применять дополнительные меры оптимизации. Например, в качестве альтернативы рассматриваются PASETO, мы наблюдаем за развитием этой технологии. Сразу мы не стали работать с ее применением, потому что на момент наших изысканий технология была довольно молодой (да и сейчас суперзрелой ее не назовешь). И нам не удалось обнаружить стабильных реализаций на нашем стеке.
Первые шаги по созданию авторизации
Среди прочих проблем, которые возникли при создании платформы, таких как организация процессов разработки и поставки, о которых ранее мы уже рассказывали, встал и вопрос организации доступа к сервисам Digital Platform. Немало копий было сломано в ходе обсуждения, как именно это реализовать, и далеко не с первой попытки мы пришли к текущему решению.
Субъекты можно было группировать по каналу, из которого они получали доступ. И организовать схему доступа вокруг этого. Когда-то мы именно так и делали. Выглядело это так: множество бэковых систем накрывается неким фасадом — API Gateway, где происходит аутентификация пользователей, которые, в свою очередь, обращаются к нему с фронта.
Такой подход имеет право на существование, хотя и обладает рядом минусов, среди которых можно выделить:
При добавлении новых компонентов системы приходится производить дополнительные настройки сети, чтобы разрешить к ним доступ.
Так как на самих сервисах нет никакой аутентификации, любой вызов из нашего сегмента сети может произойти ко всем сервисам и выполнить любую операцию. Мы столкнулись с этой проблемой, когда предоставили доступ нашим коллегам внутри организации, которые занимались развитием других систем. Они начали вызывать совсем не те операции, на которые изначально запросили доступ.
Нам пришлось писать для них отдельный адаптер и контролировать доступ к сервисам нашей системы через него.
Так как авторизация на сервисах отсутствует, мы имеем потенциальную дыру в безопасности. Если скомпрометировать API Gateway (а их потенциально может быть несколько, для каждого фронта свой шлюз) или какой-то компонент из внутреннего сегмента сети, то будет получен полный доступ к множеству сервисов.
При разборе проблем и раскопках в логах конкретного сервиса было непонятно, кто его вызывал. Каждый раз приходилось раскручивать цепочку запросов до самого начала, что было весьма трудозатратно и утомительно.
Подходы к реализации авторизации в микросервисной архитектуре
В публикации NIST 800-162 [4], посвященной разграничению доступа на основе аттрибутов (ABAC), приводится удобная терминология для описания взаимодействий между компонентами.
В работе Authentication and authorization in microservice-based systems: survey of architecture patterns [5] (также статья на Habr) исследователи Александр Барабанов и Денис Макрушин анализируют существующие архитектурные подходы для реализации аутентификации и авторизации в микросервисных приложениях, приводят плюсы и минусы различных решений. Основное внимание уделяется обзору трем основным архитектурным шаблонам межсервисных взаимодействий:
Децентрализованный шаблон;
Централизованный шаблон с единой точкой принятия решения;
Централизованный шаблон со встроенной точкой принятия решения.
Каждый из шаблонов обладает своими характерными особенностями и возможностями к применению.
При использовании децентрализованного шаблона ответственность за безопасность ложится на плечи команды разработчиков конкретного сервиса. Повышается гибкость настройки конкретного микросервиса, но усложняется задача корректного взаимодействия всей системы.
Любое изменение правил разграничения доступа требует полного тестирования всего функционала микросервиса, так как атрибуты доступа и политики находятся внутри исходного кода микросервиса. Следовательно, снижается скорость ввода микросервиса эксплуатацию и увеличиваются расходы на тестирование. Децентрализованный шаблон представлен на Рисунке 2.

Удобство использования централизованного шаблона с единой точкой принятия решения заключается в возможности централизованного управления правилами контроля доступа отстраненного от конкретных микросервисов. Появляется возможность внешнего тестирования политик управления доступа на предмет аномалий в тестовой среде.

Централизованный шаблон с механизмом встроенной точкой принятия решения отличается от единого тем, что хранение решений о доступе происходит внутри самих микросервисов. Это позволяет избежать наличие устаревших данных в кэше центра принятия решений из предыдущей модели.

Предыстория, или как мы стали платформой
Несколько лет назад (это были времена, когда логика создания продукта была сосредоточена вокруг его развития в каждом канале) мы сидели небольшой командой разработчиков и «пилили» свой уютный интернет-банк. Вроде бы даженеплохо получалось, но маятник качнулся в другую сторону.
В определенный момент стало понятно, что синхронизация развития продуктов в разных каналах требует определенного количества ресурсов, а клиентский путь по одной услуге может развиваться в нескольких каналах параллельно.
Например:
Звонок с предложением услуги из контакт-центра;
Заполнение заявки на сайте или в мобильном приложении;
Заключение сделки в отделении.
Такое развитие CJM обусловило необходимость иметь контекст пользователя и клиента. Для приложения в целом было принято решение сосредоточить логику создания и сопровождения продуктов в едином слое, к которому обращались множество фронтов. Этот слой был назван Digital Platform.
Преимущества микросервисных архитектур
В противовес монолитным архитектурам, микросервисные имеют ряд ключевых преимуществ. Для описания преимуществ можно рассматривать различные точки зрения: точка зрения бизнес-процессов, процессов разработки, процессов безопасности.
В уже ранее упомянутом отчете Oreilly читатели отметили плюсы перехода к микросервисных архитектурам (Рисунок 1). Среди плюсов фигурируют такие как: гибкость разработки, оперативная изменение технологий под бизнес требования, возможность масштабирования, повышения частоты обновлений продукта, повышение качества тестирования приложений, повышения уровня доступности и уменьшение затрат на разработку.

Важно отдельно выделить плюсы использования микросервисных архитектур с точки зрения безопасности:
Пример
Рассмотрим следующий синтетический пример. Система здравоохранения, занимающаяся результатами анализов, рентгеновскими снимками и т. Д. Информация о здоровье очень конфиденциальна и не должна разглашаться.
Результаты тестирования должны быть доступны только для:
Лечащий врач может отправить пациента к другому специалисту. Новый врач тоже должен иметь доступ к результатам анализов. Таким образом, доступ может быть предоставлен динамически.
Таким образом, каждая сущность (например, результаты тестирования, рентгеновское изображение) имеет набор правил, которым разрешен доступ пользователям и группам.
Представьте, что существует микросервис под названием «Служба результатов тестирования», работающий с результатами тестирования. Должен ли он отвечать за контроль доступа, управление разрешениями и т. Д.? Или управление разрешениями надо вынести в отдельный микросервис?
Система здравоохранения также может обрабатывать визиты к врачу. Информация о визите пациента к врачу должна быть доступна:
- пациент
- доктор
- администратор клиники
Это пример другого типа сущности, который требует ограничения доступа на уровне сущности на основе членства пользователя или группы.
Легко представить еще больше примеров, когда требуется контроль доступа на уровне сущности.
Проекции
Кроме проблемы авторизации, стоял вопрос создания оптимальной проекции данных для каждого потребителя. Предоставляя публичный API, мы постоянно получали просьбы о его доработке под того или иного потребителя, потому что каждому потребителю требовался свой набор получаемых данных (проекция).
У нас оставалось только два решения:
Создавать такие API, которые возвращали бы сущности целиком со всеми степенями вложенности, а потребители сами решали бы, какие подмножества (проекции) им использовать для своих нужд. Это порождает новую проблему, которая называется overfetching данных. Очевидным минусом такого подхода являются тяжелые DTO, передаваемые по сети;
Создавать такие API, которые возвращали бы только атомарные сущности (только один уровень вложенности). При таком подходе потребителям, чтобы сформировать у себя требуемую проекцию данных, пришлось бы посылать несколько запросов. Эта проблема также известна как underfetching данных.
На самом деле есть и третий путь — проектировать API таким образом, чтобы для каждого потребителя была возможность возвращать свой набор данных. Другими словами, свое API для каждого из потребителей. Но это достаточно трудоемкая задача, даже если вы работаете всего с тремя клиентами.
Статья — аутентификация и авторизация в микросервисных приложениях [часть 1]
Доброго времени суток, codeby.
Сегодня хочу рассказать об обеспечение безопасности микросервисного приложения. Тема довольно интересная и поистине творческая: существует довольно большое множество способов, которые меняются от системы к системе. В рамках двух статей я постараюсь дать хорошие теоретические знания вопроса и практическую реализацию одного из рецептов. Я решил разделить материал, так первая статья будет про теорию а вторая будет чисто практической. Статьи сосредоточены на механизме авторизации и аутентификации, поэтому читателю предлагается самостоятельное погружение в тему микросервисов и их архитектуры. Однако небольшие отступления, дабы читатель видел картину целиком, всё таки будут присутствовать.
В качестве приложения для примера — выбраны микросервисы, из моей статьи о docker. Читателю также предлагается ознакомиться с ними самостоятельно. Стоит сказать, что приложение было модифицировано. Фронтенд вынесен в контейнер с ngnix, о чём я также расскажу во второй части, apigetway мы перепишем в рамках второй части.
Как говорилось ранее — читателю предлагается самостоятельно ознакомится в различии микросервисной и монолитной архитектур. В контексте безопасности стоит сказать, что в монолитной системе за безопасность отвечает сам монолит. В противовес, в системе состоящей из микросервисов, чтоб удовлетворить запрос пользователя приходится вовлекать несколько микросервисов, исходя из этого напрашивается вопросы:
- какие из микросервисов должны отвечать за авторизацию, а какие за аутентификацию
- предположим, что одни из сервисов аутентифицировал пользователя, значит ли это что этому пользователю должны доверять другие микросервисы
- должны ли микросервисы доверять другу
- должны ли все микросервисы иметь доступ ко всем микросервисам, т.е. имеют ли право все микросервисы обращаться друг к другу
Как раз в этом месте и начинается творчество. Проблема заключается в том, что ответы на приведённые вопросы сильно различаются. Нельзя не заметить, что различия коррелируют с особенностью рассматриваемой системы — ответы, которые правильны для системы А будут в корне не верны для системы Б и так далее.
Кейсы аутентификации и авторизации встречается во всех системах. Различие между монолитом и микросервисами (в контексте данных проблем) в том, что в микросервисной системе всегда присутствует вопрос о том, какие из микросервисов должны отвечать за авторизацию и аутентификацию.
Словарь
Рассуждая теоретически, очень важно говорить на одном языке, поэтому давайте для начала определимся с некоторыми моментами.
Задача аутентификации — убедиться, что пользователь — тот за кого себя выдаёт.
Задача авторизации — убедиться, что пользователь имеет право делать то или иное действие в системе.
Данные бывают передаваемыми и хранимыми. Передаваемые данные — это данные которые “гуляют” от микросервиса до микросервиса. Хранимые — это данные которые хранятся в базах данных микросервисов.
Область действия — идентификатор для группы ресурсов, которые необходимо защитить. Например, все конечные точки способные изменить местоположение Пети, должны входить в группу location_information_write. Этакие наименования прав.
Маркер доступа — подписанный объект, используемый для предоставления доступа к микросервисам. Микросервис может запросить маркер доступа к любой области действий, если доступ разрешен — микросервис начинает взаимодействовать с разрешенной зоной.
OAuth и OpenId Connect — мы будем использовать эти протоколы для аутентификации и авторизации, реализацию возьмём из IdentityServer.
Аутентификация
Разобравшись с понятиями давайте приступим к размышлениям. Напомни, что раньше мы использовали архитектуру frontend for backend, где в качестве бэкэнда мы использовали микросервисы. Тогда каждый фрагмент фронтенда либо прорисовывался, либо нет — в зависимости от того был ли запущен сервис. Сейчас же давайте изменим архитектуру на нечто такое:
Что произошло: я вынес фронтенд часть на волю ngnix, действительно, нет особой необходимости иметь целый .net core проект, который существует лишь для того, чтобы рендерить заглавную страницу сайта, ngnix легковесней, дешевле и быстрее, этого вполне достаточно чтобы сделать выбор в его пользу. Появилось бизнесс-требование, которое гласит: “Необходимо дать пользователю возможность предустанавливать свою страну и город, для корректного вывода погоды и курса валют”. Вот у нас и появился функционал, который должен быть разграничен пользовательским контекстом. Так для Пети из Москвы погода и курс рубля к доллару будет отличаться от Тараса из Харькова (курс валюты для Тараса будет представлен как гривна к доллару).
Появился микросервис Login, в рамках которого и строится дальнейшее проектирование, предполагается что микросервис логин будет аутентифицировать пользователей, так как только Петя может менять свои настройки, ну суть ясна я думаю.
Взглянем ещё раз на новую архитектуру. Микросервис Login отвечает за вход Тараса и Пети в систему, однако за запросы Пети и Тараса всё ещё отвечает API Gateway (вернее он вообще отвечает за то что запросы могут выполнять только вошедшие в систему пользователи). Следовательно микросервис API Gateway должен знать аутентифицирован ли пользователь отправивший запрос или нет.
Тут нам на помощь придёт промежуточное ПО, которое перенаправляет пользователей, которые не вошли в систему, в микросервис Login. Сам же микросервис Login решает как именно пользователь будет входить в систему и проводит его через процесс входа. В рамках статьи, Петя и Тарас смогут попасть в систему двумя способами:
Вне зависимости от способа входа, микросервис Login должен предоставлять подтверждение API Gateway того, что пользователь аутентифицирован, в таком виде в котором API Gateway предоставляет возможность проверить подлинность. Для этого существуют различные протоколы, в данном случае мы будем использовать OpenId Connect.
Хочу обратить ваше внимание, что аутентификация пользователя происходит на периферии системы, т.е. она проводится микросервисом, получившем запрос непосредственно от пользователя (через промежуточное ПО перенаправления). Это хорошо зарекомендовавший себя принцип разработки систем безопасности для микросервисов: аутентификация пользователя происходит на периферии системы.
Авторизация пользователей
После аутентификации пользователя — мы знаем кто он такой, однако в нормальных системах присутствует система прав, а значит знания, что пользователь является тем за кого себя выдаёт не гарантирует того что у пользователя есть разрешение на совершение того или иного действия. Ну банальный пример: уборщице Таси не нужно давать разрешения на визирование документов отправленных Тарасом для Петра. Также понятно, что система должна отклонять запрос на изменение местоположения Тараса направленного от имени Петра.
Так как мы имеем дело с микросервисной архитектурой, нам нужно понять какой сервис должен отвечать за авторизацию запросов. И вот ответ: поскольку один микросервис это всегда одна бизнес-возможность, мы вполне можем оставить авторизацию в конкретном сервисе. То есть, если Тарас имеет право на визирования документов для Петра, проверку этого визирования можно и нужно оставить в микросервисе документов. Так мы приходим к тому, что авторизация — это тоже часть бизнес возможности, если конкретней то это бизнес-правило.
Теперь поразмышляем о том как это реализовать. Несомненно проясняется факт, что мы должны передавать идентифицированную информацию пользоватяля от микросервиса к микросервису. Так сказать прокидывать её. Эту ответственность мы делегируем нашему Api Gateway так как именно он первым принимает запросы от пользователя, он должен каким то образом модифицировать пользовательский запрос.
Доверие микросервисов друг к другу
Поговорим о моменте, который нередко (разумеется во вред) упускается из вида. Смоделируем ситуацию атаки, допустим злоумышленник смог завладеть микросервисом валют и собирается отправить от его имени запрос на изменение логина и пароля Тараса на микросервис Login. В сценарии, где микросервисы доверяют друг другу и ничем не ограничены — мы, как blue team, потерпели сокрушительное фиаско. Однако, если голова нам дана “не чтоб шапку носить” и мы ограничили доступ к микросервису Login (разумно, чтоб его мог вызывать только Api Gateway, так как он находится на периферии) то всё будет хорошо.
Так насколько же микросервис должен доверять другому микросервису? Ответ на это вопрос, к сожалению, когда как. Это очень сильно зависит от проектируемых систем, от орг. структур, от требований соблюдений нормативных стандартов и т.д.
Чтобы обеспечить ограничение по взаимодействию — мы создадим в микросервисе Login области действий (см словарь). При необходимости вызова другого микросервиса, вызывающий микросервис должен будет запросить доступ у микросервиса Login в виде маркера доступа к конкретной области действия. К тому же мы должны передавать эти данные в зашифрованном виде, а не обычным текстом.
Google OAuth
Напоследок хочу сказать пару слов о том, как работает гугл аутентификация.
Давайте взглянем на картинку:
Процесс описан сверху вниз. В данном случае Client — это фронтенд часть приложения которое мы обсуждаем. Server — это его серверная часть, которая представлена у нас микросервисом Login. Google API Server — апи гугла, с которым мы будем взаимодействовать, а OAuth Dialog — это тот самый диалог, которые предоставляет гугл для аутентификации юзеров. Для использование google oauth нам нужен api-ключ: не имеет смысла расписывать пошагово как его получить, поэтому вот:
Implement social authentication with React RESTful API
Ну а в следующей части я расскажу и покажу как всё это реализовать.
Текущая реальность и планы развития
Используя такую комбинацию технологий, мы получили комплексное решение со стороны безопасности и архитектуры:
Независимый от конкретного языка программирования механизм авторизации для компонентов системы (Digital Platform). Следуй стандарту, используй GraphQL, размечай поля директивами — и вперед;
Разделили авторизацию и бизнес-логику на уровне архитектуры. Разработчики доменных сервисов сосредоточены на создании бизнес-функционала и не думают о деталях реализации авторизации;
Позволили владельцам сервисов сосредоточиться на логике их реализации и не фокусироваться на том, какие именно проекции данных могут потребоваться конкретным потребителям;
Удобное управление ролями через внешний сервис, которое не блокируется развитием сервисов и само не блокирует их;
Оценить плюсы такого подхода как Sidecar, который позволил независимо релизить различные компоненты системы. Настоятельно рекомендую присмотреться к той части приложения, которую вы распространяете как библиотека, и вынести ее в Sidecar. Это особенно актуально для активно развивающихся систем, которые часто релизятся в процессе непрерывной поставки;
Популяризировать внутри организации современную технологию. Что ни говорите, а банки традиционно относят к консервативным структурам, тогда как современные разработчики любят
«стильно, модно, молодежно»пробовать новые решения и технологии.Повышение Multitenancy — возможности повторно использовать компоненты системы гораздо шире, чем рамки одного проекта и даже организации. Активность в этом направлении (платформизация) позволяет нам экономить на создании типовых решений при запуске новых продуктов.
Надеемся, что история была интересной и наш опыт будет полезен для вас.
Заключение
В статье предложена универсальная модель для авторизации доступа множеству пользователей к множеству ресурсов с минимальными потерями по производительности, позволяющая делать эффективное кеширование и хранение промежуточных данных на микросервисах, для сборки результата авторизации just-in-time.
Предложена метрика (в виде коэффициента), для оценки работы авторизации микросервисов с учетом требований работы всего комплекса и показано, как он может меняться в зависимости от подхода, а именно наличия/отсутствия кеша, хранения ролей в JWT токене и т.д. Не показано, что этот коэффициент всегда растет с увеличением количества под в системе.
Предложенная модель данных позволяет разделить данные между частями микросервисной архитектуры, тем самым снизив требования к железу, дает возможность работать только с теми данными, которые нужны в конкретный момент времени конкретному сервису, не пытаться искать в огромном массиве все подряд или пытаться искать данные в полностью обобщенном хранилище.
Показано, что при малом количестве микросервисов нет смысла проводить кеширование на клиенте авторизации, так как это приведет к большей нагрузке на ЦПУ. Предоставлены данные, которые позволяют сделать вывод, что необходимо балансировать ресурсы в зависимости от размеров системы, если она слишком мала, то есть смысл нагружать больше сеть, но при увеличении и разрастании выгоднее добавить пару ядер в микросервисы, для обеспечения работы кешей и разгрузки сети, микросервисов авторизационных данных.
Выводы и дальнейшая работа
В настоящей работе были рассмотрены лучшие практики по обеспечению аутентификации и авторизации в микросервисных приложениях, а также представлены основные архитектурные подходы. Построение оптимальной архитектуры является важнейшей задачей при проектировании любых программных продуктов.
В связи с этим фактором и факторами озвученными выше, на рынке появляется потребность в архитекторах безопасности (security architect), в людях, которые обладают компетенциями и опытом в построении защищенных систем. Переход на микросервисные архитектуры меняет подход к обеспечению безопасности распределенных приложений.
Дальнейшая работа в этом направлении заключается в:
Анализе существующих решений и подходов парадигмы Zero Trust Architecture (ZTA) [6], которая заключается в нулевом доверии к компонентам системы и к переду с концепции «защиты на основе периметра/сегмента» к концепции «защиты конкретных ресурсов»;
Создании учебно-лабораторного стенда для реализации представленных микросервисных архитектур и проведении анализа эффективности.
Заключение первой части
В этой статье мы постарались дать теоретический и терминологический фундамент, который понадобится нам создании работающего решения в следующих статьях.
Stay tuned.
Минимальная реализация интеграция Identity Server в ваше приложение выглядит так:
public void Configuration(IAppBuilder app)
{ var factory = new IdentityServerServiceFactory(); factory.UseInMemoryClients(Clients.Get()) .UseInMemoryScopes(Scopes.Get()) .UseInMemoryUsers(Users.Get()); var options = new IdentityServerOptions { SiteName = Constants.IdentityServerName, SigningCertificate = Certificate.Get(), Factory = factory, }; app.UseIdentityServer(options);
}Минимальная реализация интеграции веб-клиента с Identity Server:
public void Configuration(IAppBuilder app)
{ app.UseCookieAuthentication(new CookieAuthenticationOptions { AuthenticationType = "Cookies" }); app.UseOpenIdConnectAuthentication(new OpenIdConnectAuthenticationOptions { ClientId = Constants.ClientName, Authority = Constants.IdentityServerAddress, RedirectUri = Constants.ClientReturnUrl, ResponseType = "id_token", Scope = "openid email", SignInAsAuthenticationType = "Cookies", });
}Минимальная реализация интеграции веб-API с Identity Server:
public void Configuration(IAppBuilder app)
{ app.UseIdentityServerBearerTokenAuthentication( new IdentityServerBearerTokenAuthenticationOptions { Authority = Constants.IdentityServerAddress, RequiredScopes = new[] { "write" }, ValidationMode = ValidationMode.Local, // credentials for the introspection endpoint ClientId = "write", ClientSecret = "secret" }); app.UseWebApi(WebApiConfig.Register());
}