Oauth 2.0 -> oauth 2.1. что дальше?
Итак, мы с некой долей скептицизма рассмотрели авторизационные потоки, которые нам предлагает фреймворк OAuth 2.0. Давайте же теперь разбираться и отвечать на вопрос, поставленный в заголовке к самой статье. В каком направлении и как развивается OAuth 2.0?
За период, начиная с момента перевода OAuth 2.0 из черновика в статус стандарта, до настоящего времени разработчики стандарта продолжали активно делать работу над ошибками, которая появлялась в свет в виде новых RFC и черновиков в дополнение к OAuth 2.0:
Итогом почти десятилетней работы стало появление драфта
период действия которого истекает 31.01.2021.
И здесь интригующий напрашивается вопрос: «будет ли продлен драфт или перейдет в статус стандарта?»
Драфт консолидировал в себе изменения всех более поздних публикаций. Наиболее значимые из них:
(1) Потоки Implicit grant (response_type=token) и Resource Owner Password Credentials исключаются из документа.
(2)
Аuthorization code grant расширили кодом PKCE (
) таким образом, что единственный вариант использования Аuthorization code grant в соответствии с этой спецификацией требует добавления механизма PKCE;
Clients MUST use «code_challenge» and «code_verifier» and authorization servers MUST enforce their use except under the conditions described in Section 9.8. In this case, using and enforcing «code_challenge» and «code_verifier» as described in the following is still RECOMMENDED.
Введение
Стоит ли винить во всем разработчиков, как это принято делать чаще всего? На мой взгляд, не стоит. У разработчика часто стоит задачей реализовать ту или иную функциональность по неким требованиям. Посмотрим же внимательнее на OAuth 2.0.
Фреймворк предлагает воспользоваться правилами по организации потоков авторизации:
А также требования к форматам обмена.
«Что в описании стандарта может приводить к небезопасным реализациям на практике?»Я пока оставлю этот вопрос открытым, и предлагаю читателю самостоятельно при дальнейшем изучении OAuth 2.0 и прочтении статьи делать свои выводы. На протяжении этой статьи я же буду приводить свое видение ответа на этот вопрос.
Аутентификация на основе токенов
Аутентификация на основе токенов в последние годы стала очень популярна из-за распространения одностраничных приложений, веб-API и интернета вещей. Чаще всего в качестве токенов используются Json Web Tokens (JWT). Хотя реализации бывают разные, но токены JWT превратились в стандарт де-факто.
При аутентификации на основе токенов состояния не отслеживаются. Мы не будем хранить информацию о пользователе на сервере или в сессии и даже не будем хранить JWT, использованные для клиентов.
Процедура аутентификации на основе токенов:
1 Словесное описание решаемой задачи
Компания ОАО «ПьемЧай» ежедневно требует работы от миллиона сотрудников и сотни тысяч гостей. Все сотрудники пьют чай и в этом состоит их работа. В компании есть гости, которые пить чай не могут, для них доступны опции, которые позволяют им видеть какой чай они смогут пить на своей будущей работе, а так же лучших сотрудников года, месяца и недели.
Некоторые сотрудники в пандемию работают удаленно и доступ к чаю им предоставляет курьерская служба Кракен, прямо к точке доставки. Удаленные сотрудники могут получать чай только из той точки доставки, к которой они привязаны. Находясь в офисе они все равно могут пить чай как обычные сотрудники.
1 немного теории
Основной задачей авторизации доступа является разграничение доступа к целевому объекту на основании данных о субъекте, запрашивающем доступ, и свойствах объекта.
При проектировании любой системы авторизации следует обращать внимания на характеристики, описываемые ниже.
Формируем request для обновления токена
val refreshRequest = TokenRequest.Builder(
authServiceConfig,
AuthConfig.CLIENT_ID
)
.setGrantType(GrantTypeValues.REFRESH_TOKEN)
.setScopes(AuthConfig.SCOPE)
.setRefreshToken(TokenStorage.refreshToken)
.build()Тут нам важно учесть 2 строчки:
.setGrantType(GrantTypeValues.REFRESH_TOKEN)
.setRefreshToken(TokenStorage.refreshToken)В качестве grantType передаем refreshToken, и передаем непосредственно сам refreshToken из вашего хранилища, который был получен при авторизации.
Формируем request:
val endSessionRequest = EndSessionRequest.Builder(authServiceConfig)
//Требуется для некоторых сервисов, idToken получается при авторизации аналогично accessToken и refreshToken
.setIdTokenHint(idToken)
// uri на который произойдет редирект после успешного логаута, не везде поддерживается
.setPostLogoutRedirectUri(AuthConfig.LOGOUT_CALLBACK_URL.toUri())
.build()1 Время восстановления/энтропия входных параметров
Авторизация принимает решение о разграничении доступа на основе множества входных параметров. Если таковых будет слишком много, либо мерность множеств окажется слишком большой, то авторизация будет терять слишком много ресурсов на выполнение ненужных операций. Это как сортировать данные пузырьком и qsort. Не следует выполнять ненужные операции.
Если у вашей системы есть на входе A,B,C,D,E,F — факты о пользователе, то если вы будете объединять все в одно, то получите A * B * C * D * E * F комбинаций, которые невозможно эффективно кешировать. По возможности следует найти такую комбинацию входных, что бы у вас было A * B * C и D * E * F комбинаций, а еще лучше A * B, C * D, E * F, которые вы уже легко сможете вычислять и кешировать.
Эта характеристика очень важна так же для построения системы правил, которые будут предоставлять пользователям доступы.
2 Детализация авторизации
Второй характеристикой является предел детализации авторизации, когда дальнейшее разграничение доступа становится уже невозможным. Например вы можете разграничивать доступ к ручкам микросервиса, но уже не иметь возможности ограничить доступ к сущностям, которые она выдает. Либо доступ к сущности вы ограничиваете, но вот операции доступны все и всем. И т.д.
От того, насколько детально нужно работать авторизации зависит как время восстановления, так и энтропия входных данных, т.к. работать вам придется со все увеличивающимся массивом входных данных. Разумеется, если вы не предпринимаете попытки для того, что бы уровни детализации друг на друга влияли аддитивно, а не мультипликативно.
2 обобщенная модель данных
Прежде чем проектировать, необходимо договориться о терминах и структурах данных с их взаимосвязями.
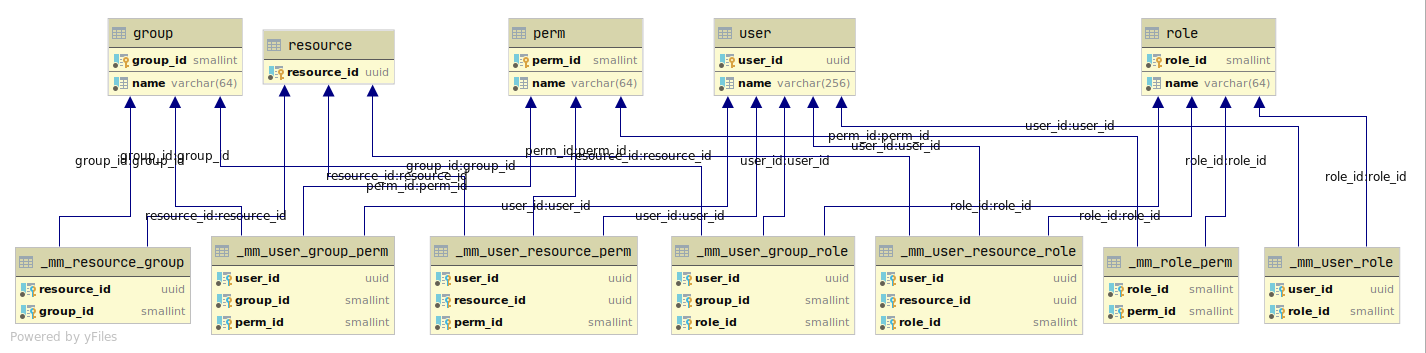
Вы можете убрать ненужные вам связи, главное — это то, что вам необходимо ограничивать.
Детально опишем все имеющиеся определения с которыми будем дальше работать.
Выполняем сформированный request:
authorizationService.performTokenRequest(refreshRequest) { response, ex ->
when {
response != null -> emitter.onSuccess(response)
ex != null -> emitter.tryOnError(ex)
else -> emitter.tryOnError(IllegalStateException("response and exception is null"))
}
}Формируем custom tabs intent:
val customTabsIntent = CustomTabsIntent.Builder().build()1 Пользователь
Субъект, чей доступ необходимо авторизовать.
Данное определение задает субъекты, которые могут быть как людьми, так и автоматическими системами, которые получают доступ к вашим ресурсам. У любого пользователя могут быть свои роли, разрешения и группы.
10 О кешировании данных
Основной проблемой при работе авторизации является точка в которой необходимо кешировать результаты, что бы работало быстрее все, да еще желательно так, что бы нагрузка на ЦПУ не была высокой. Вы можете поместить все ваши данные в память и спокойно их читать, но это дорогое решение и не все готовы будут себе его позволить, особенно если требуется всего лишь пара ТБ ОЗУ.
Правильным решением было бы найти такие места, которые бы позволяли с минимальными затратами по памяти давать максимум быстродействия.
Предлагаю решить такую задачу на примере ролей пользователя и некоего микросервиса, которому нужно проверять наличие роли у пользователя. Разумеется в данном случае можно сделать карту (Пользователь, Роль) -> Boolean. Проблема в том, что все равно придется на каждую пару делать запрос на удаленный сервис.
Даже если вам данные будут предоставлять за 0,1 мс, то ваш код будет работать все равно медленно. Очевидным решением будет кешировать сразу роли пользователя! В итоге у нас будет кеш Пользователь -> Роль[]. При таком подходе на какое-то время микросервис сможет обрабатывать запросы от пользователя без необходимости нагружать другие микросервисы.
Разумеется читатель спросит, а что если ролей у пользователя десятки тысяч? Ваш микросервис всегда работает с ограниченным количеством ролей, которые он проверяет, соответственно вы всегда можете либо захардкодить список, либо найти все аннотации, собрать все используемые роли и фильтровать только их.
Полагаю, что ход мыслей, которому стоит следовать, стал понятен.
2 Сервис
Множество ресурсов объединенных в единое целое, как пример сервис проектов.
В рамках микросервисной архитектуры основным направлением разработки является выделение таких множеств ресурсов, которые можно назвать сервисом, так что бы программно-аппаратная часть могла эффективно обрабатывать заданный объем данных.
3 Ресурс
Единичный объем информации для работы авторизации, например проект.
В рамках сервиса могут существовать ресурсы, доступ к которым необходимо ограничивать. Это может быть как файл в облачном сервисе, так и заметка, видимая ограниченному кругу лиц.
4 Разрешение
Право пользователя выполнять операцию над сервисом и/или ресурсом.
5 Роль
Множество разрешений, по сути под словом роль всегда подразумевается множество разрешений.
Следует отметить, что в системе может не быть ролей и напрямую задаваться набор разрешений для каждого пользователя в отдельности. Так же в системе могут отсутствовать разрешения (речь про хранение их в виде записей БД), но быть роли, при этом такие роли будут называться статичными, а если в системе существуют разрешения, тогда роли называются динамическими, так как можно в любой момент поменять, создать или удалить любую роль так, что система все равно продолжит функционировать.
Ролевые модели позволяют как выполнять вертикальное, так и горизонтальное разграничение доступа (описание ниже). Из типа разграничения доступа следует, что сами роли делятся на типы:
Но отсюда следует вопрос, если у пользователя есть глобальная роль и локальная, то как определить его эффективные разрешения? Поэтому авторизация должна быть в виде одной из форм:
Подробное описание использования типа ролей и формы авторизации ниже.
Роль имеет следующие связи:
Следует отметить, что реализация статичных ролей требует меньше вычислительных ресурсов (при определении эффективных разрешений пользователя будет на один джойн меньше), но вносить изменения в такую систему можно только релизным циклом, однако при большом числе ролей гораздо выгоднее использовать разрешения, так как чаще всего микросервису нужно строго ограниченное их число, а ролей с разрешением может быть бесконечное число. Для больших проектов, стоит задуматься о том, что бы работать только с динамическими ролями.
6 Группа
Используя группы можно объединить множество ресурсов, в том числе расположенных в разных сервисах в одно целое, и управлять доступом к ним используя одну точку. Это позволяет гораздо проще и быстрее реализовывать предоставление доступа пользователя к большим массивам информации, не требуя избыточных данных в виде записи на каждый доступ к каждому ресурсу по отдельности вручную или автоматически. По сути вы решаете задачу предоставления доступа к N ресурсам создавая 1 запись.
Группы используются исключительно для горизонтального разграничения доступа (описание ниже). Даже если вы будете использовать группы для доступа к сервисам, то это все равно горизонтальное разграничение доступа, потому что сервис — это совокупность ресурсов.
Группа имеет следующие связи:
7 Вертикальное и горизонтальное разграничение доступа.
Самым простым способом представить себе работу авторизации — это нарисовать таблицы на каждого пользователя и каждый сервис, где колонки будут задавать разрешения, а строки — ресурсы, на пересечении ставятся галочки там, где доступ разрешен (привет excel-warrior’ам).
Для обеспечения доступа вы можете либо связать пользователя с ролью, что даст вам заполнение соответствующих разрешению ролей колонок в таблицах — такое разграничение называется вертикальным. Либо вы можете связать пользователя, роль и ресурс, что ограничит доступ до отдельного ресурса — такое предоставление доступ является горизонтальным.
8 Глобальность/локальность авторизации доступа в микросервисах
Несмотря на то, что все роли могут хранится в единой БД, то вот связи между ними и пользователями хранить все вместе на всю вашу огромную систему — это типичный антипаттерн, делать так является грубейшей ошибкой, это все равно что POSIX права на файлы хранить в облачном сервисе, вместе с таблицей inode.
9 Конъюнктивная/дизъюнктивная форма авторизации
Из-за того, что у теперь у нас существуют два варианта наборов разрешений пользователя, то можно выделить два варианта, как объединить все вместе:
Одним из важных преимуществ конъюнктивной формы является жесткий контроль за всеми операциями, которые может выполнять пользователь, а именно — без глобального разрешения пользователь не сможет получить доступ в следствие ошибки на месте. Так же реализация в виде программного продукта горазо проще, так как достаточно сделать последовательность проверок, каждая из которых либо успешна, либо бросает исключение.
Дизъюнктивная форма позволяет гораздо проще делать супер-админов и контролировать их численность, однако на уровне отдельных сервисов потребует написания своих алгортмов авторизации, которые в начале получит все разрешения пользователя, а уже потом либо успешно пройдет, либо бросит исключение.
Рекомендуется всегда использовать только конъюнктивную форму авторизации в виду ее большей гибкости и возможности снизить вероятность появления инцидентов по утечке данных. Так же именно конъюнктивная форма авторизации имеет большую устойчивость к ДДОС атакам в виду использования меньшего объема ресурсов.
Ее проще реализовать и использовать, отлаживать. Разумеется можно и дизъюнктивную форму натравить на анализ аннотаций метода и поиск соответствующих сервисов, но запросы вы отправлять будете скорее всего синхронно, один за другим, если же будете делать асинхронные вызовы, то много ресурсов будет уходить в пустоту, оно вам надо?
3 как использовать обобщенную модель данных
Теперь, определившись с терминами, можно разобрать несколько задачек, для того, что бы видеть как на практике применить материал.
1 Закрытый онлайн аукцион
Организатор может создать аукцион, пригласить участников. Участник может принять приглашение, сделать ставку.
Для того, что бы организатор мог создавать аукционы — нужно создать глобальную роль Организатор и при попытке создать аукцион — требовать эту роль. Созданные приглашения уже хранят в себе идентификаторы пользователей, поэтому когда пользователь делает ставку в аукционе, то это будет простейший запрос наличия записи перед вставкой ставки в аукцион.
2 Логистика
Огромная логистическая компания требует разграничить доступы для супервизоров и продавцов да еще с учетом региона. Работа такова, что продавец может выставить заявку на получение товара, а супервизор уже решает кому и сколько достанется. Соответственно продавец может видеть свой магазин и все товары в нем, а так же созданные им заявки, статус их обработки.
Для реализации такого функционала нам потребуется реестр регионов и магазинов в качестве отдельного микросервиса, назовем его С1. Заявки и историю будем хранить на С2. Авторизация — А.Далее при обращении продавца для получения списка его магазинов (а у него может быть их несколько)
, С1 вернет только те, в которых у него есть меппинг (Пользователь, Магазин), так как ни в какие регионы он не добавлен и для продавца регионы всегда пустое множество. Разумеется при условии, что у пользователя есть разрешение просматривать список магазинов — посредством микросервиса А.
Работа супервизора будет выглядеть немного иначе, вместо регистрации супервизора на каждый магазин региона, мы сделаем меппинги (Пользователь, Регион) и (Регион, Магазин) в этом случае для супервизора у нас всегда будет список актуальных магазинов с которыми он работает.
3 Секретные части документа
Некое министерство обязано выкладывать документы в общественный доступ, но часть документа является не предназначенной для показа любому желающему (назовем эту часть — номер телефона). Сам документ состоит из блоков, каждый из которых может быть либо текстом, либо номером телефона — скрытой частью, которую видеть могут только особые пользователи, подписавшие соглашение о неразглашении.
Когда пользователь обращается в сервис для получения блоков документа, микросервис в авторизации проверяет роль пользователя на чтение документов, далее в БД каждый блок имеет флаг — секрет. У документа есть меппинг (Пользователь, Документ) — список пользователей, которые подписали соглашение.
4 Команда и ее проекты
Если у вас большая команда, и много проектов, и такая команда у вас не одна, то координировать работу их будет той еще задачей. Особенно если таких команд у вас тысячи. Каждому разработчику вы доступы не пропишите, а если у вас человек еще и в нескольких командах работает, то разграничивать доступ станет еще сложнее.
Такую проблему проще всего решить при помощи групп.Группа будет объединять все необходимые проекты в одно целое. При добавлении участника в команду, добавляем меппинг (Пользователь, Группа, Роль).
Допустим, что Вася — разработчик и ему нужно вызвать метод develop на микросервисе для выполнения своих обязанностей. Этот метод потребует у Васи роли в проекте — Разработчик.Как мы уже договаривались — регистрация пользователя в каждый проект для нас недопустима.
Поэтому микросервис проектов обратится в микросервис групп, что бы получить список групп, в которых Вася — Разработчик. Получив список этих групп можно легко проверить уже в БД микросервиса проектов — есть ли у проекта какая-нибудь из полученных групп и на основании этого предоставлять или запрещать ему доступ.
Открываем страницу логаута:
private val logoutResponse = registerForActivityResult(
ActivityResultContracts.StartActivityForResult()
) {}
logoutResponse.launch(endSessionIntent)Пользователь переходит на страницу логаута, где чистится его сессия в браузере.
После логаута нам нужно перехватить редирект, чтобы вернуться в приложение. Не все сервисы позволяют указывать URL редиректа после логаута (github не позволяет). Поэтому пользователю нужно будет нажать на крестик в CCT.
После ручного закрытия активити с CCT мы получим result=cancelled, потому что редиректа в приложение не было.
В нашем примере с Github мы будем в любом случае очищать сессию и переходить на страницу входа в приложение.
2 Архитектура решения
Для решения поставленной задачи нам необходимы следующие микросервисы:
- Ролевая модель для глобальной авторизации запросов
- Чайный сервис для предоставления возможности пить чай и получать статистику по выпитому
- Кракен — гейт с проверкой доступа к точке, все остальные проверки совершит чайный сервис
Графически это будет выглядеть так:
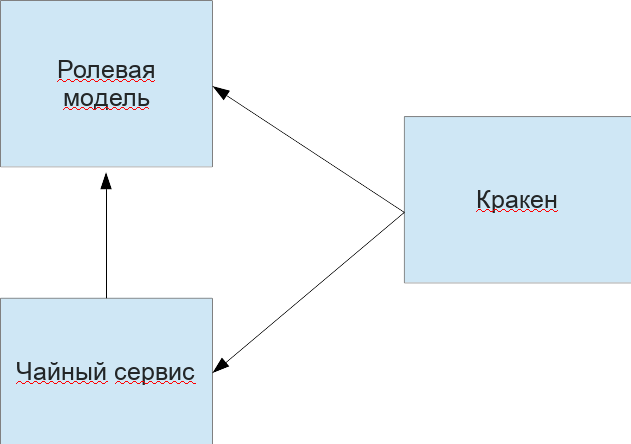
В качестве БД будем использовать PostgreSQL.Предусмотрим следующие обязательные для решения задачи роли:
- Сотрудник — для возможности пить чай;
- Удаленный сотрудник — для доступа к микросервису кракена (так как сотрудники в офисе не должны иметь возможности пить чай через точки распрастранения чая);
- Кракен — учетная запись микросервиса, что бы была возможность обращаться к API чайного сервиса;
- Авторизационная учетная запись — для предоставления доступа микросервисов к ролевой модели.
5 реализация микросервисов
Для реализации воспользуемся Spring фреймворком, он довольно медленный, но зато на нем легко и быстро можно реализовывать приложения. Так как за перформансом мы не гонимся, то попробуем на нем достичь скромных 1к рпс авторизованных пустых запросов (хотя люди на спринге умудрялись 100к пустых запросов проворачивать [1]).
Весь проект поделен на несколько репозиториев:
Для начала разберемся с базой данных ролевой модели:
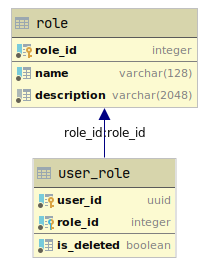
Browser
Второй вариант — открыть страницу во внешнем браузере, установленном на устройстве.
Преимущества:
Недостатки:
Chromecustomtabs, safarivc
ChromeCustomTabs(CCT) и SafariViewController(SafariVC) аналогично браузеру позволяют легко реализовать открытие веб-страниц в вашем приложении.
Они закрывают недостатки WebView:
Недостатки браузера тоже частично закрываются:
CCT изначально был сделан только для Chrome, а сейчас поддерживается в разных браузерах. Помимо него, в Android есть еще TrustedWebActivity. Подробнее про них можно почитать на официальной странице.
Этот подход является самым оптимальным. Он закрывает почти все недостатки предыдущих двух подходов.
Client id и secret
Задолго до того, как вы разрешили Terrible Pun of the Day получить доступ к контактам, Client и Authorization Server установили рабочие отношения. Authorization Server сгенерировал Client ID и Client Secret (иногда их называют
App IDApp Secret
) и отправил их Client’у для дальнейшего взаимодействия в рамках OAuth.
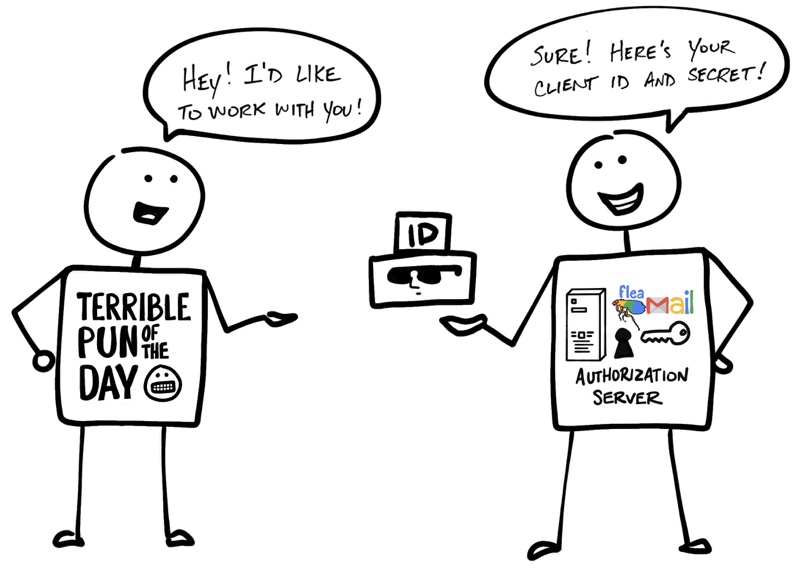
«— Привет! Я хотел бы работать с тобой! — Да не вопрос! Вот твои Client ID и Secret!»
Название намекает, что Client Secret должен держаться в тайне, чтобы его знали только Client и Authorization Server. Ведь именно с его помощь Authorization Server подтверждает истинность Client’а.
Id token — это jwt
ID Token
— это особым образом отформатированная строка символов, известная как JSON Web Token или JWT
(иногда токены JWT произносят как «jots»)
. Сторонним наблюдателям JWT может показаться непонятной абракадаброй, однако
Client
может извлечь из JWT различную информацию, такую как ID, имя пользователя, время входа в учетную запись, срок окончания действия
ID Token
‘а, наличие попыток вмешательства в JWT. Данные внутри
ID Token
‘а называются
заявками[claims]
В случае OIDC также имеется стандартный способ, с помощью которого Client может запросить дополнительную информацию о личности [identity] от Authorization Server’а, например, адрес электронной почты, используя Access Token.
Mitm-атака для перехвата кода
Одной из реализаций OAuth является реализация с помощью внешнего браузера.
В таком случае код возвращается обратно в приложение с помощью системной функции: когда внутри браузера происходит редирект на URL, который может обработать ваше приложение — открывается ваше приложение.
Именно в момент, когда система ищет приложение для обработки URL редиректа, возможен перехват редиректа зловредным приложением. Злоумышленник может создать приложение, которое перехватывает такие же редиректы, как у вас. Утекают все данные, которые находятся в строке редиректа.

Именно поэтому в редиректе нужно возвращать промежуточный код, а не токен. Иначе токен будет доступен чужому приложению.
При использовании обычного Authorization Code Flow чужое приложение (Malicious app) потенциально может получить код и обменять его на токен, аналогично тому, как это сделано в вашем приложении (Real app). Но с использованием code_verifier и code_challenge зловредный перехват становится бессмысленным.
Стоит отметить, что такая атака не сработает, если использовать universal links (ios) и applink (android). Чтобы открыть редирект-ссылку в приложении, необходимо положить на сервер json-файл с описанием подписи вашего приложения.
Но часто мы не можем добавить json-файл на сервер, если авторизуемся с помощью внешнего сервиса, который разрабатываем не мы. Поэтому не всегда это может помочь.
Oauth и flow
Когда речь идет про авторизацию и аутентификацию, используются такие понятия как OAuth2 и OpenID. В статье я не буду их раскрывать, на Хабре уже есть такой материал:
Ниже мы рассмотрим детали, касающиеся мобильной разработки. Для наших целей неважны различия между OAuth2 и OpenID, поэтому дальше мы будем использовать общий термин OAuth.
В OAuth существуют различные flow, но не все подходят для использования в приложении:
Webview
Преимущества:
Недостатки:
Авторизация
Теперь откроем страницу авторизации с использованием CCT.
Для работы с CCT и выполнения автоматических операций обмена кода на токен библиотека AppAuth предоставляет сущность AuthorizationService. Эта сущность создается при входе на экран. При выходе с экрана она должна очиститься. В примере это делается внутри ViewModel экрана авторизации.
Создаем в init:
private val authService: AuthorizationService = AuthorizationService(getApplication())Очищаем в onCleared:
authService.dispose()Для открытия страницы авторизации в CCT нужен интент. Для этого получаем AuthorizationRequest на основе заполненных раньше данных в AuthConfig:
private val serviceConfiguration = AuthorizationServiceConfiguration(
Uri.parse(AuthConfig.AUTH_URI),
Uri.parse(AuthConfig.TOKEN_URI),
null, // registration endpoint
Uri.parse(AuthConfig.END_SESSION_URI)
)
fun getAuthRequest(): AuthorizationRequest {
val redirectUri = AuthConfig.CALLBACK_URL.toUri()
return AuthorizationRequest.Builder(
serviceConfiguration,
AuthConfig.CLIENT_ID,
AuthConfig.RESPONSE_TYPE,
redirectUri
)
.setScope(AuthConfig.SCOPE)
.build()
}Создаем интент:
// тут можно настроить вид chromeCustomTabs
val customTabsIntent = CustomTabsIntent.Builder().build()
val openAuthPageIntent = authService.getAuthorizationRequestIntent(
getAuthRequest(),
customTabsIntent
)После этого открываем активити по интенту. Нам необходимо обработать результат активити, чтобы получить код.
Поэтому используем ActivityResultContracts. Также можно использовать startActivityForResult.
private val getAuthResponse = registerForActivityResult(ActivityResultContracts.StartActivityForResult()) {
val dataIntent = it.data ?: return
handleAuthResponseIntent(dataIntent)
}
getAuthResponse.launch(openAuthPageIntent)Под капотом будут открыты активити из библиотеки, которые возьмут на себя ответственность открытия CCT и обработку редиректа. А в активити вашего приложения уже прилетит результат операции.

Внутри openAuthPageIntent будет зашита вся информация, которую мы раньше указывали в AuthConfig, а также сгенерированный code_challenge.
Авторизация для приложений, имеющих серверную часть
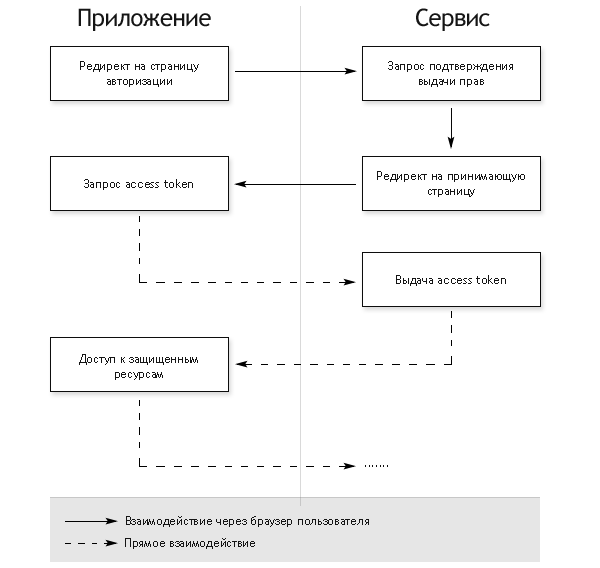
- Редирект на страницу авторизации
- На странице авторизации у пользователя запрашивается подтверждение выдачи прав
- В случае согласия пользователя, браузер редиректится на URL, указанный при открытии страницы авторизации, с добавлением в GET-параметры специального ключа — authorization code
- Сервер приложения выполняет POST-запрос с полученным authorization code в качестве параметра. В результате этого запроса возвращается access token
Это самый сложный вариант авторизации, но только он позволяет сервису однозначно установить приложение, обращающееся за авторизацией (это происходит при коммуникации между серверами на последнем шаге). Во всех остальных вариантах авторизация происходит полностью на клиенте и по понятным причинам возможна маскировка одного приложения под другое. Это стоит учитывать при внедрении OAuth-аутентификации в API сервисов.
Авторизация полностью клиентских приложений
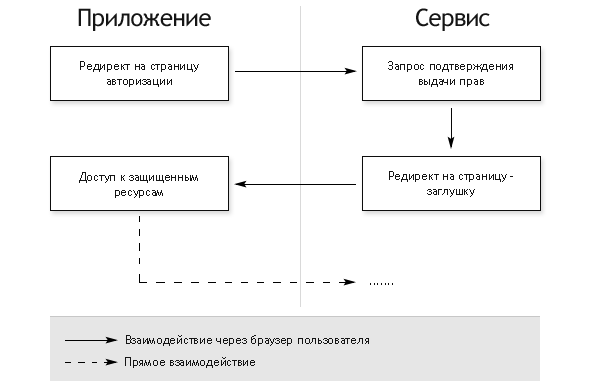
- Открытие встроенного браузера со страницей авторизации
- У пользователя запрашивается подтверждение выдачи прав
- В случае согласия пользователя, браузер редиректится на страницу-заглушку во фрагменте (после #) URL которой добавляется access token
- Приложение перехватывает редирект и получает access token из адреса страницы
Этот вариант требует поднятия в приложении окна браузера, но не требует серверной части и дополнительного вызова сервер-сервер для обмена
authorization codeaccess token
Аутентификация в соцсетях
Уверен, эта картинка знакома всем:
Аутентификация или авторизация?
Некоторые путают термины «аутентификация» и «авторизация». Это разные вещи.
Ещё тут?
Поздравляю, вы успешно дочитали длинную, нудную и скучную статью.
Беспарольная аутентификация
Первой реакцией на термин «беспарольная аутентификация» может быть «Как аутентифицировать кого-то без пароля? Разве такое возможно?»
В наши головы внедрено убеждение, что пароли — абсолютный источник защиты наших аккаунтов. Но если изучить вопрос глубже, то выяснится, что беспарольная аутентификация может быть не просто безопасной, но и безопаснее традиционного входа по имени и паролю. Возможно, вы даже слышали мнение, что пароли устарели.
Беспарольная аутентификация — это способ конфигурирования процедуры входа и аутентификации пользователей без ввода паролей. Идея такая:
Вместо ввода почты/имени и пароля пользователи вводят только свою почту. Ваше приложение отправляет на этот адрес одноразовую ссылку, пользователь по ней кликает и автоматически входит на ваш сайт / в приложение. При беспарольной аутентификации приложение считает, что в ваш ящик пришло письмо со ссылкой, если вы написали свой, а не чужой адрес.
Есть похожий метод, при котором вместо одноразовой ссылки по SMS отправляется код или одноразовый пароль. Но тогда придётся объединить ваше приложение с SMS-сервисом вроде twilio (и сервис не бесплатен). Код или одноразовый пароль тоже можно отправлять по почте.
И ещё один, менее (пока) популярный (и доступный только на устройствах Apple) метод беспарольной аутентификации: использовать Touch ID для аутентификации по отпечаткам пальцев. Подробнее о технологии.
Если вы пользуетесь Slack, то уже могли столкнуться с беспарольной аутентификацией.
Браузер отсутствует
В Android, в отличие от iOS, может не быть браузера. Но он нам понадобится для использования CCT, причем с поддержкой этого способа.
Кроме Chrome, этот функционал поддерживается в SBrowser, Firefox и всех остальных современных браузерах. Но даже если такового у пользователя нет, откроется обычный браузер.
На официальной странице рассказывают,как проверить браузеры с поддержкой CCT.
Варианты реализации oauth
Мы рассмотрели OAuth flow для мобильных приложений и увидели, на какие нюансы стоит обратить внимание при реализации.
Существует несколько вариантов реализации.
Виды авторизации
Существует несколько моделей авторизации. Три основные — ролевая, избирательная и мандатная.
- Ролевая модель. Администратор назначает пользователю одну или несколько ролей, а уже им выдает разрешения и привилегии. Эта модель применяется во многих прикладных программах и операционных системах.
Например, все пользователи с ролью «Кассир» имеют доступ к кассовым операциям в бухгалтерской системе, а пользователи с ролью «Товаровед» — нет, зато у них есть доступ к складским операциям, при этом обе роли имеют доступ к общей ленте новостей.
- Избирательная модель. Права доступа к конкретному объекту выдают конкретному пользователю. При этом право определять уровень доступа имеет либо владелец конкретного объекта (например, его создатель), либо суперпользователь (по сути, владелец всех объектов в системе). Кроме того, пользователь, обладающий определенным уровнем доступа, может передавать назначенные ему права другим.
Например, пользователь А, создав текстовый файл, может назначить пользователю Б права на чтение этого файла, а пользователю В — права на его чтение и изменение. При этом пользователи Б и В могут передать свои права пользователю Г.
Избирательная модель применяется в некоторых операционных системах, например в семействах Windows NT (в том числе в Windows 10) и Unix. По этой же модели предоставляется доступ, скажем, к документам на диске Google.
- Мандатная модель. Администратор назначает каждому элементу системы определенный уровень конфиденциальности. Пользователи получают уровень доступа, определяющий, с какими объектами они могут работать. Обычно такая модель является иерархической, то есть высокий уровень доступа включает в себя права на работу и со всеми младшими уровнями.
Мандатная модель авторизации применяется в системах, ориентированных на безопасность, и чаще всего она используется для организации доступа к гостайне и в силовых ведомствах.
Например, в организации может быть пять уровней доступа. Пользователь, имеющий доступ к файлам 3-го уровня, может также открывать файлы 1-го и 2-го уровня, но не может работать с файлами 4-го и 5-го уровня.
Восстановление предыдущей авторизации
Обычно,
access token
имеет ограниченный срок годности. Это может быть полезно, например, если он передается по открытым каналам. Чтобы не заставлять пользователя проходить авторизацию после истечения срока действия
access token
‘а, во всех перечисленных выше вариантах, в дополнение к
access token
‘у может возвращаться еще
refresh token
. По нему можно получить
access token
Дамы и господа, встречайте: oauth 2.0
— это стандарт безопасности, позволяющий одному приложению получить разрешение на доступ к информации в другом приложении. Последовательность действий для выдачи разрешения
[permission]
(или
согласия[consent]
) часто называют
авторизацией[authorization]
или даже
делегированной авторизацией[delegated authorization]
. С помощью этого стандарта вы позволяете приложению считать данные или использовать функции другого приложения от вашего имени, не сообщая ему свой пароль. Класс!
В качестве примера представим, что вы обнаружили сайт с названием «Неудачный каламбур дня» [Terrible Pun of the Day] и решили зарегистрироваться на нем, чтобы ежедневно получать каламбуры в виде текстовых сообщений на телефон. Сайт вам очень понравился, и вы решили поделиться им со всеми знакомыми. Ведь жуткие каламбурчики нравятся всем, не так ли?

«Неудачный каламбур дня: Слышали о парне, который потерял левую половину тела? Теперь он всегда прав!» (перевод примерный, т.к. в оригинале своя игра слов — прим. перев.)
Понятно, что писать каждому человеку из контакт-листа не вариант. И, если вы хотя бы чуточку похожи на меня, то пойдете на всё, чтобы избежать лишней работы. Благо Terrible Pun of the Day может сам пригласить всех ваших друзей! Для этого лишь нужно открыть ему доступ к электронной почте контактов — сайт сам отправит им приглашения (OAuth рулит)!
Двухфакторная аутентификация (2fa)
Двухфакторная аутентификация (2FA) улучшает безопасность доступа за счёт использования двух методов (также называемых факторами) проверки личности пользователя. Это разновидность многофакторной аутентификации. Наверное, вам не приходило в голову, но в банкоматах вы проходите двухфакторную аутентификацию: на вашей банковской карте должна быть записана правильная информация, и в дополнение к этому вы вводите PIN.
Если кто-то украдёт вашу карту, то без кода он не сможет ею воспользоваться. (Не факт! — Примеч. пер.) То есть в системе двухфакторной аутентификации пользователь получает доступ только после того, как предоставит несколько отдельных частей информации.
Использовать sdk сервиса, через который вы хотите авторизоваться
Плюсы:
Минусы:
Использование SDK мы рассматривать в текущей статье не будем, потому что для этого нужно изучать документацию SDK.
Использовать библиотеки
Библиотеки должны поддерживать протоколы OAuth и OpenId и позволять общаться с любыми сервисами по этим протоколам. Примеры: AppAuth IOSAppAuth AndroidAuth0 Android
При использовании этого подхода нужно убедиться, что сервер аутентификации работает в соответствии с протоколом, и вам не придется костылить библиотеку, чтобы связаться с ним.
Если разобраться с библиотекой и знать, как она работает, реализация получается достаточно простой. Но на это требуется время.
Реализация авторизации будет универсальная для разных сервисов, не придется подключать дополнительные зависимости и писать много кода для каждого внешнего сервиса, если таких несколько.
Учтите, что реализация библиотеки может быть не совсем удобной для встраивания в ваше приложение. Используемые подходы общения с библиотекой могут отличаться от принятых в команде, и нужно будет писать обертки-бриджи. Пример: AppAuth в Android использует AsyncTask под капотом, но в приложении вы, скорее всего, используете корутины. Но обычно такие вещи можно интегрировать.
В дальнейшем в статье мы рассмотрим реализацию входа с использованием библиотеки AppAuth. Тому есть несколько причин:
Критический взгляд на oauth 2.0
Изучая последовательно стандарт, можно столкнуться с рядом неоднозначных рекомендаций, что, в прочем, не является редким явлением зачастую в документации. Предлагаю сейчас и заняться выявлением этих несоответствий. Хотя кому-то я могу показаться излишне придирчивой. Я этого не исключаю и буду рада услышать встречное мнение читателя.
Рассмотрим первый из наиболее распространенных в реализации потоков с момента создания стандарта: Authorization Code Grant. В самом начале стандарта его разработчики предлагают ознакомиться
документа представлением. А далее уже рассматривается каждый индивидуально и, в частности,
. Но что мы видим:
На представлении потока Authorization Code Grant почему-то отсутствует ресурсный сервер. Наверное, у многих потребителей стандарта может возникнуть вопрос, что же делать дальше с полученным токеном?
Логаут
В большинстве случаев при пользовательском логауте в приложении нужно почистить токены/файлы/БД/кеши.
Минусы oauth 2.0
Во всей этой красоте есть и ложка дегтя, куда без нее?
OAuth 2.0 — развивающийся стандарт. Это значит, что спецификация еще не устоялась и постоянно меняется, иногда довольно заметно. Так, что если вы решили поддержать стандарт прямо сейчас, приготовьтесь к тому, что его поддержку придется подпиливать по мере изменения спецификации. С другой стороны, это также значит, что вы можете поучаствовать в процессе написания стандарта и внести в него свои идеи.
Безопасность OAuth 2.0 во многом основана на SSL. Это сильно упрощает жизнь разработчикам, но требует дополнительных вычислительных ресурсов и администрирования. Это может быть существенным вопросом в высоко нагруженных проектах.
Но это ещё не всё… пожалуйста, поприветствуйте openid connect!
OAuth 2.0 разработан только для
авторизации
— для предоставления доступа к данным и функциям от одного приложения другому.
Обновление токенов
С использованием OAuth вам не нужно забывать об обновлении токенов.
Общая настройка
Первым делом зарегистрируем приложение OAuth в Github.
При регистрации установите CALLBACK_URL для вашего приложения на сервисе. На этот URL будет происходить перенаправление после авторизации, и ваше приложение будет его перехватывать.
Понятия и термины
Перед рассмотрением отдельно каждого из потоков, дадим определения базовой терминологии, используемой в стандарте (читателю, знакомому с терминологией OAuth 2.0, данный абзац можно пропустить).
Теперь можем перейти к рассмотрению каждого из потоков детальнее.
Поток oauth
Только что мы прошли через то, что обычно называют
потоком[flow]
OAuth. В нашем примере этот поток состоит из видимых шагов, а также из нескольких невидимых шагов, в рамках которых два сервиса договариваются о безопасном обмене информацией. В предыдущем примере с Terrible Pun of the Day используется наиболее распространенный поток OAuth 2.0, известный как поток «с кодом авторизации»
[«authorization code» flow]
Прежде чем углубиться в подробности работы OAuth, давайте поговорим о значении некоторых терминов:
- Resource Owner:

Это вы! Вы владеете своими учетными данными, своими данными и управляете всеми действиями, которые могут быть произведены с вашими аккаунтами.
- Client:

Приложение (например, сервис Terrible Pun of the Day), которое хочет получить доступ или выполнить определенные действия от имени Resource Owner‘а.
- Authorization Server:
Приложение, которое знает Resource Owner‘а и в котором у Resource Owner‘а уже есть учетная запись.
- Resource Server:
Программный интерфейс приложения (API) или сервис, которым Client хочет воспользоваться от имени Resource Owner‘а.
- Redirect URI:

Ссылка, по которой Authorization Server перенаправит Resource Owner‘а после предоставления разрешения Client‘у. Иногда ее называют «Возвратным URL» («Callback URL»).
- Response Type:
Тип информации, которую ожидает получить Client. Самым распространенным Response Type‘ом является код, то есть Client рассчитывает получить Authorization Code.
- Scope:

Это подробное описание разрешений, которые требуются Client‘у, такие как доступ к данным или выполнение определенных действий.
- Consent:
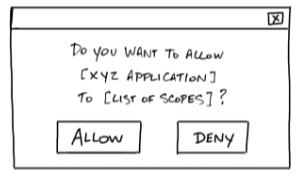
Authorization Server берет Scopes, запрашиваемые Client‘ом, и спрашивает у Resource Owner‘а, готов ли тот предоставить Client‘у соответствующие разрешения.
- Client ID:
Этот ID используется для идентификации Client‘а на Authorization Server‘е.
- Client Secret:

Это пароль, который известен только Client‘у и Authorization Server‘у. Он позволяет им конфиденциально обмениваться информацией.
- Authorization Code:

Временный код с небольшим периодом действия, который Client предоставляет Authorization Server‘у в обмен на Access Token.
- Access Token:
Ключ, который клиент будет использовать для связи с Resource Server‘ом. Этакий бейдж или ключ-карта, предоставляющий Client‘у разрешения на запрос данных или выполнение действий на Resource Server‘е от вашего имени.
Примечание: иногда Authorization Server и Resource Server являются одним и тем же сервером. Однако в некоторых случаях это могут быть разные серверы, даже не принадлежащие к одной организации. Например, Authorization Server может быть сторонним сервисом, которому доверяет Resource Server.
Теперь, когда мы ознакомились с основными понятиями OAuth 2.0, давайте вернемся к нашему примеру и подробно рассмотрим, что происходит в потоке OAuth.
Принцип работы authorization code flow with pkce
Для мобильных клиентов рекомендуется использовать Authorization Code Flow c дополнением: Authorization Code Flow with Proof Key for Code Exchange (PKCE). Использовать именно этот flow важно для безопасности пользовательского входа в приложение. Рассмотрим его особенности.
Этот flow основан на обычном Authorization Code Flow. Сначала вспомним его реализацию:
Разница между авторизацией, аутентификацией и идентификацией
Авторизацию не следует путать с идентификацией и аутентификацией пользователя. Она происходит по завершении этих процессов.
Реализация android
Подключим библиотеку в проект:
implementation 'net.openid:appauth:0.9.1'Запишем все настройки OAuth в один объект, чтобы было легко с ним работать:
Реализация в android-приложении
Давайте посмотрим, как можно реализовать OAuth в вашем Android-приложении с использованием AppAuth. Весь код доступен на Github.
Приложение простое: отображение информации о моем github-профиле.
Для этого при каждом запуске приложения будем открывать страницу github-авторизации. После успешной авторизации переводим пользователя на главную страницу, откуда можно получить информацию о текущем пользователе.
При реализации нам необходимо разобраться с 3 ключевыми моментами:
Реализовать вручную
Реализовать логику вручную внутри собственного приложения с использованием WebView или других реализаций (CCT/SafariVC).
Плюс:
Минус:
Ручную реализацию мы рассматривать не будем, потому что она индивидуальна для каждого приложения и сервиса.
Редирект в chrome не срабатывает
Как уже упоминали выше, для редиректа обратно в приложение лучше использовать кастомную схему, чтобы редирект не был перехвачен браузерами.
В процессе тестирования реализации OAuth в Android мы столкнулись с тем, что Chrome с использованием CCT после успешной авторизации не перебрасывал нас обратно в приложение на некоторых устройствах. На это заведен баг в трекере.
В Chrome сделали обновление, которое запрещает без пользовательского намерения переходить по URL с кастомной схемой. Это блокирует попадание пользователя в зловредное приложение.
Для обхода этого ограничения сделали веб-страничку, на которую браузер редиректит после успешной авторизации. Веб-страница автоматически пытается сделать редирект уже внутрь приложения. Если этого не происходит, то есть Chrome заблокировал переход, пользователь может нажать на кнопку enter и перейти явно. Этот подход сработал.
Чем отличаются openid и oauth
Не смотря на то, что объяснений на эту тему уже было много, она по-прежнему вызывает некоторое непонимание.
Заключение
В статье предложена универсальная модель для авторизации доступа множеству пользователей к множеству ресурсов с минимальными потерями по производительности, позволяющая делать эффективное кеширование и хранение промежуточных данных на микросервисах, для сборки результата авторизации just-in-time.
Предложена метрика (в виде коэффициента), для оценки работы авторизации микросервисов с учетом требований работы всего комплекса и показано, как он может меняться в зависимости от подхода, а именно наличия/отсутствия кеша, хранения ролей в JWT токене и т.д. Не показано, что этот коэффициент всегда растет с увеличением количества под в системе.
Предложенная модель данных позволяет разделить данные между частями микросервисной архитектуры, тем самым снизив требования к железу, дает возможность работать только с теми данными, которые нужны в конкретный момент времени конкретному сервису, не пытаться искать в огромном массиве все подряд или пытаться искать данные в полностью обобщенном хранилище.
Показано, что при малом количестве микросервисов нет смысла проводить кеширование на клиенте авторизации, так как это приведет к большей нагрузке на ЦПУ. Предоставлены данные, которые позволяют сделать вывод, что необходимо балансировать ресурсы в зависимости от размеров системы, если она слишком мала, то есть смысл нагружать больше сеть, но при увеличении и разрастании выгоднее добавить пару ядер в микросервисы, для обеспечения работы кешей и разгрузки сети, микросервисов авторизационных данных.
Формируем итоговый интент:
val endSessionIntent = authService.getEndSessionRequestIntent(
endSessionRequest,
customTabsIntent
)11 Выводы по обобщенной модели
Предложенная модель дает возможность сделать масштабируемую систему авторизации. Позволяет сделать глобальное разграничение один раз и далее только корректировать, добавляя новые роли, разрешения, группы, все более детализируя доступ к каждому конкретному ресурсу каждому пользователю.
Памятка для разработчиков
Имеющийся сейчас у меня опыт работы с системами, реализующими OAuth 2, хотела бы оставить в статье, так как надеюсь, что он может оказаться кому-то полезен и позволит качественнее защищать наши с вами данные в сети.
Позволю себе обозначенные правила к авторизационным потокам и приложениям, которые их реализуют, разложить в виде матрицы принятия решений:
Для того или иного приложения и выбираемого подхода существуют свои плюсы и минусы. Вкратце посмотрим на «JavaScript application with no backend» и «JavaScript application with a backend» и дадим ключевые рекомендации к реализациям:
Приведенные выше заметки, на мой взгляд, могут быть полезны при составлении чек-листа требований к системам, отвечающим за безопасность процессов авторизации/аутентификации пользователей. Возможно, я что-то важное, на ваш взгляд, упускаю. Поможете мне дополнить список требований и ограничений?