1 Словесное описание решаемой задачи
Компания ОАО «ПьемЧай» ежедневно требует работы от миллиона сотрудников и сотни тысяч гостей. Все сотрудники пьют чай и в этом состоит их работа. В компании есть гости, которые пить чай не могут, для них доступны опции, которые позволяют им видеть какой чай они смогут пить на своей будущей работе, а так же лучших сотрудников года, месяца и недели.
Некоторые сотрудники в пандемию работают удаленно и доступ к чаю им предоставляет курьерская служба Кракен, прямо к точке доставки. Удаленные сотрудники могут получать чай только из той точки доставки, к которой они привязаны. Находясь в офисе они все равно могут пить чай как обычные сотрудники.
1 немного теории
Основной задачей авторизации доступа является разграничение доступа к целевому объекту на основании данных о субъекте, запрашивающем доступ, и свойствах объекта.
При проектировании любой системы авторизации следует обращать внимания на характеристики, описываемые ниже.
1 Время восстановления/энтропия входных параметров
Авторизация принимает решение о разграничении доступа на основе множества входных параметров. Если таковых будет слишком много, либо мерность множеств окажется слишком большой, то авторизация будет терять слишком много ресурсов на выполнение ненужных операций. Это как сортировать данные пузырьком и qsort. Не следует выполнять ненужные операции.
Если у вашей системы есть на входе A,B,C,D,E,F — факты о пользователе, то если вы будете объединять все в одно, то получите A * B * C * D * E * F комбинаций, которые невозможно эффективно кешировать. По возможности следует найти такую комбинацию входных, что бы у вас было A * B * C и D * E * F комбинаций, а еще лучше A * B, C * D, E * F, которые вы уже легко сможете вычислять и кешировать.
Эта характеристика очень важна так же для построения системы правил, которые будут предоставлять пользователям доступы.
2 Детализация авторизации
Второй характеристикой является предел детализации авторизации, когда дальнейшее разграничение доступа становится уже невозможным. Например вы можете разграничивать доступ к ручкам микросервиса, но уже не иметь возможности ограничить доступ к сущностям, которые она выдает. Либо доступ к сущности вы ограничиваете, но вот операции доступны все и всем. И т.д.
От того, насколько детально нужно работать авторизации зависит как время восстановления, так и энтропия входных данных, т.к. работать вам придется со все увеличивающимся массивом входных данных. Разумеется, если вы не предпринимаете попытки для того, что бы уровни детализации друг на друга влияли аддитивно, а не мультипликативно.
2 обобщенная модель данных
Прежде чем проектировать, необходимо договориться о терминах и структурах данных с их взаимосвязями.
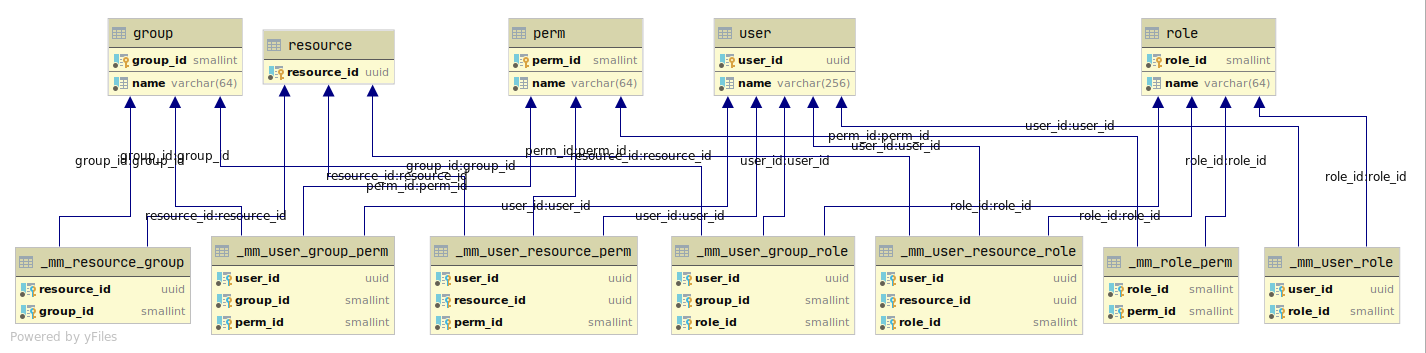
Вы можете убрать ненужные вам связи, главное — это то, что вам необходимо ограничивать.
Детально опишем все имеющиеся определения с которыми будем дальше работать.
1 Пользователь
Субъект, чей доступ необходимо авторизовать.
Данное определение задает субъекты, которые могут быть как людьми, так и автоматическими системами, которые получают доступ к вашим ресурсам. У любого пользователя могут быть свои роли, разрешения и группы.
10 О кешировании данных
Основной проблемой при работе авторизации является точка в которой необходимо кешировать результаты, что бы работало быстрее все, да еще желательно так, что бы нагрузка на ЦПУ не была высокой. Вы можете поместить все ваши данные в память и спокойно их читать, но это дорогое решение и не все готовы будут себе его позволить, особенно если требуется всего лишь пара ТБ ОЗУ.
Правильным решением было бы найти такие места, которые бы позволяли с минимальными затратами по памяти давать максимум быстродействия.
Предлагаю решить такую задачу на примере ролей пользователя и некоего микросервиса, которому нужно проверять наличие роли у пользователя. Разумеется в данном случае можно сделать карту (Пользователь, Роль) -> Boolean. Проблема в том, что все равно придется на каждую пару делать запрос на удаленный сервис.
Даже если вам данные будут предоставлять за 0,1 мс, то ваш код будет работать все равно медленно. Очевидным решением будет кешировать сразу роли пользователя! В итоге у нас будет кеш Пользователь -> Роль[]. При таком подходе на какое-то время микросервис сможет обрабатывать запросы от пользователя без необходимости нагружать другие микросервисы.
Разумеется читатель спросит, а что если ролей у пользователя десятки тысяч? Ваш микросервис всегда работает с ограниченным количеством ролей, которые он проверяет, соответственно вы всегда можете либо захардкодить список, либо найти все аннотации, собрать все используемые роли и фильтровать только их.
Полагаю, что ход мыслей, которому стоит следовать, стал понятен.
2 Сервис
Множество ресурсов объединенных в единое целое, как пример сервис проектов.
В рамках микросервисной архитектуры основным направлением разработки является выделение таких множеств ресурсов, которые можно назвать сервисом, так что бы программно-аппаратная часть могла эффективно обрабатывать заданный объем данных.
3 Ресурс
Единичный объем информации для работы авторизации, например проект.
В рамках сервиса могут существовать ресурсы, доступ к которым необходимо ограничивать. Это может быть как файл в облачном сервисе, так и заметка, видимая ограниченному кругу лиц.
4 Разрешение
Право пользователя выполнять операцию над сервисом и/или ресурсом.
5 Роль
Множество разрешений, по сути под словом роль всегда подразумевается множество разрешений.
Следует отметить, что в системе может не быть ролей и напрямую задаваться набор разрешений для каждого пользователя в отдельности. Так же в системе могут отсутствовать разрешения (речь про хранение их в виде записей БД), но быть роли, при этом такие роли будут называться статичными, а если в системе существуют разрешения, тогда роли называются динамическими, так как можно в любой момент поменять, создать или удалить любую роль так, что система все равно продолжит функционировать.
Ролевые модели позволяют как выполнять вертикальное, так и горизонтальное разграничение доступа (описание ниже). Из типа разграничения доступа следует, что сами роли делятся на типы:
Но отсюда следует вопрос, если у пользователя есть глобальная роль и локальная, то как определить его эффективные разрешения? Поэтому авторизация должна быть в виде одной из форм:
Подробное описание использования типа ролей и формы авторизации ниже.
Роль имеет следующие связи:
Следует отметить, что реализация статичных ролей требует меньше вычислительных ресурсов (при определении эффективных разрешений пользователя будет на один джойн меньше), но вносить изменения в такую систему можно только релизным циклом, однако при большом числе ролей гораздо выгоднее использовать разрешения, так как чаще всего микросервису нужно строго ограниченное их число, а ролей с разрешением может быть бесконечное число. Для больших проектов, стоит задуматься о том, что бы работать только с динамическими ролями.
6 Группа
Используя группы можно объединить множество ресурсов, в том числе расположенных в разных сервисах в одно целое, и управлять доступом к ним используя одну точку. Это позволяет гораздо проще и быстрее реализовывать предоставление доступа пользователя к большим массивам информации, не требуя избыточных данных в виде записи на каждый доступ к каждому ресурсу по отдельности вручную или автоматически. По сути вы решаете задачу предоставления доступа к N ресурсам создавая 1 запись.
Группы используются исключительно для горизонтального разграничения доступа (описание ниже). Даже если вы будете использовать группы для доступа к сервисам, то это все равно горизонтальное разграничение доступа, потому что сервис — это совокупность ресурсов.
Группа имеет следующие связи:
7 Вертикальное и горизонтальное разграничение доступа.
Самым простым способом представить себе работу авторизации — это нарисовать таблицы на каждого пользователя и каждый сервис, где колонки будут задавать разрешения, а строки — ресурсы, на пересечении ставятся галочки там, где доступ разрешен (привет excel-warrior’ам).
Для обеспечения доступа вы можете либо связать пользователя с ролью, что даст вам заполнение соответствующих разрешению ролей колонок в таблицах — такое разграничение называется вертикальным. Либо вы можете связать пользователя, роль и ресурс, что ограничит доступ до отдельного ресурса — такое предоставление доступ является горизонтальным.
8 Глобальность/локальность авторизации доступа в микросервисах
Несмотря на то, что все роли могут хранится в единой БД, то вот связи между ними и пользователями хранить все вместе на всю вашу огромную систему — это типичный антипаттерн, делать так является грубейшей ошибкой, это все равно что POSIX права на файлы хранить в облачном сервисе, вместе с таблицей inode.
9 Конъюнктивная/дизъюнктивная форма авторизации
Из-за того, что у теперь у нас существуют два варианта наборов разрешений пользователя, то можно выделить два варианта, как объединить все вместе:
Одним из важных преимуществ конъюнктивной формы является жесткий контроль за всеми операциями, которые может выполнять пользователь, а именно — без глобального разрешения пользователь не сможет получить доступ в следствие ошибки на месте. Так же реализация в виде программного продукта горазо проще, так как достаточно сделать последовательность проверок, каждая из которых либо успешна, либо бросает исключение.
Дизъюнктивная форма позволяет гораздо проще делать супер-админов и контролировать их численность, однако на уровне отдельных сервисов потребует написания своих алгортмов авторизации, которые в начале получит все разрешения пользователя, а уже потом либо успешно пройдет, либо бросит исключение.
Рекомендуется всегда использовать только конъюнктивную форму авторизации в виду ее большей гибкости и возможности снизить вероятность появления инцидентов по утечке данных. Так же именно конъюнктивная форма авторизации имеет большую устойчивость к ДДОС атакам в виду использования меньшего объема ресурсов.
Ее проще реализовать и использовать, отлаживать. Разумеется можно и дизъюнктивную форму натравить на анализ аннотаций метода и поиск соответствующих сервисов, но запросы вы отправлять будете скорее всего синхронно, один за другим, если же будете делать асинхронные вызовы, то много ресурсов будет уходить в пустоту, оно вам надо?
3 как использовать обобщенную модель данных
Теперь, определившись с терминами, можно разобрать несколько задачек, для того, что бы видеть как на практике применить материал.
1 Закрытый онлайн аукцион
Организатор может создать аукцион, пригласить участников. Участник может принять приглашение, сделать ставку.
Для того, что бы организатор мог создавать аукционы — нужно создать глобальную роль Организатор и при попытке создать аукцион — требовать эту роль. Созданные приглашения уже хранят в себе идентификаторы пользователей, поэтому когда пользователь делает ставку в аукционе, то это будет простейший запрос наличия записи перед вставкой ставки в аукцион.
2 Логистика
Огромная логистическая компания требует разграничить доступы для супервизоров и продавцов да еще с учетом региона. Работа такова, что продавец может выставить заявку на получение товара, а супервизор уже решает кому и сколько достанется. Соответственно продавец может видеть свой магазин и все товары в нем, а так же созданные им заявки, статус их обработки.
Для реализации такого функционала нам потребуется реестр регионов и магазинов в качестве отдельного микросервиса, назовем его С1. Заявки и историю будем хранить на С2. Авторизация — А.Далее при обращении продавца для получения списка его магазинов (а у него может быть их несколько)
, С1 вернет только те, в которых у него есть меппинг (Пользователь, Магазин), так как ни в какие регионы он не добавлен и для продавца регионы всегда пустое множество. Разумеется при условии, что у пользователя есть разрешение просматривать список магазинов — посредством микросервиса А.
Работа супервизора будет выглядеть немного иначе, вместо регистрации супервизора на каждый магазин региона, мы сделаем меппинги (Пользователь, Регион) и (Регион, Магазин) в этом случае для супервизора у нас всегда будет список актуальных магазинов с которыми он работает.
3 Секретные части документа
Некое министерство обязано выкладывать документы в общественный доступ, но часть документа является не предназначенной для показа любому желающему (назовем эту часть — номер телефона). Сам документ состоит из блоков, каждый из которых может быть либо текстом, либо номером телефона — скрытой частью, которую видеть могут только особые пользователи, подписавшие соглашение о неразглашении.
Когда пользователь обращается в сервис для получения блоков документа, микросервис в авторизации проверяет роль пользователя на чтение документов, далее в БД каждый блок имеет флаг — секрет. У документа есть меппинг (Пользователь, Документ) — список пользователей, которые подписали соглашение.
4 Команда и ее проекты
Если у вас большая команда, и много проектов, и такая команда у вас не одна, то координировать работу их будет той еще задачей. Особенно если таких команд у вас тысячи. Каждому разработчику вы доступы не пропишите, а если у вас человек еще и в нескольких командах работает, то разграничивать доступ станет еще сложнее.
Такую проблему проще всего решить при помощи групп.Группа будет объединять все необходимые проекты в одно целое. При добавлении участника в команду, добавляем меппинг (Пользователь, Группа, Роль).
Допустим, что Вася — разработчик и ему нужно вызвать метод develop на микросервисе для выполнения своих обязанностей. Этот метод потребует у Васи роли в проекте — Разработчик.Как мы уже договаривались — регистрация пользователя в каждый проект для нас недопустима.
Поэтому микросервис проектов обратится в микросервис групп, что бы получить список групп, в которых Вася — Разработчик. Получив список этих групп можно легко проверить уже в БД микросервиса проектов — есть ли у проекта какая-нибудь из полученных групп и на основании этого предоставлять или запрещать ему доступ.
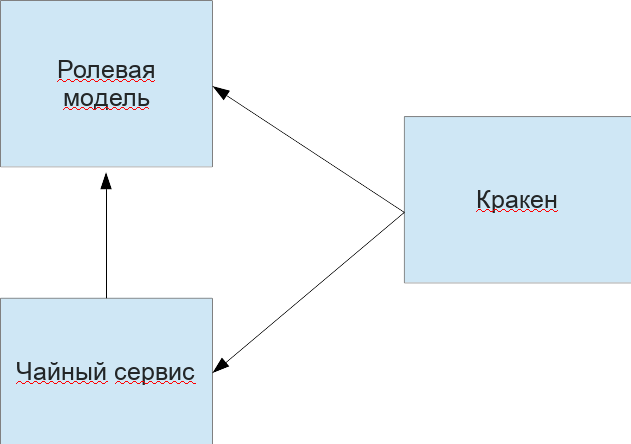
2 Архитектура решения
Для решения поставленной задачи нам необходимы следующие микросервисы:
- Ролевая модель для глобальной авторизации запросов
- Чайный сервис для предоставления возможности пить чай и получать статистику по выпитому
- Кракен — гейт с проверкой доступа к точке, все остальные проверки совершит чайный сервис
Графически это будет выглядеть так:
В качестве БД будем использовать PostgreSQL.Предусмотрим следующие обязательные для решения задачи роли:
- Сотрудник — для возможности пить чай;
- Удаленный сотрудник — для доступа к микросервису кракена (так как сотрудники в офисе не должны иметь возможности пить чай через точки распрастранения чая);
- Кракен — учетная запись микросервиса, что бы была возможность обращаться к API чайного сервиса;
- Авторизационная учетная запись — для предоставления доступа микросервисов к ролевой модели.
5 реализация микросервисов
Для реализации воспользуемся Spring фреймворком, он довольно медленный, но зато на нем легко и быстро можно реализовывать приложения. Так как за перформансом мы не гонимся, то попробуем на нем достичь скромных 1к рпс авторизованных пустых запросов (хотя люди на спринге умудрялись 100к пустых запросов проворачивать [1]).
Весь проект поделен на несколько репозиториев:
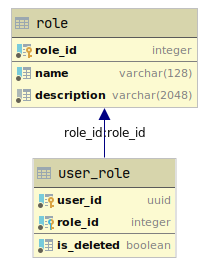
Для начала разберемся с базой данных ролевой модели:
Can i re-use some parts ?
If you find anything useful please feel free to borrow ideas and
code. Any comments, examples or code is welcome also.
Overview
auth.php provides the abstract class that needs to be implemented
with various subclasses. It needs:
- an
AuthProvider, which is used as the authentication backend - an
AuthTokenStore, which is used to store locally authentication tokens - an
AuthWebTransmitter, which is responsible of sending auth tokens
oeauth.php shows how to build a custom class. This one uses OpenERP
as authentication backend, and classical PHP $_SESSION magic
variable for session token storage. And a re-usable Javascript pattern is used
as a way to propagate tokens to other domains.
Pjsip.conf
Тут давайте немного тормознем, и посмотрим на опции.
disable multi domain
Это опция интересна тем, что по умолчанию она no. Серьезно, чаще всего инсталляции идут без поддержки домена. Но значение по-умолчанию дает астериску команду проверять домены. Если у Вас нет доменов, не поленитесь, поставьте здесь yes. Это сэкономит по 2 обращения на каждую авторизацию и каждый инвайт. База скажет вам спасибо.
endpoint identifier order
Ps: диалплан
Первый же вопрос в комментариях — а как звонить между филиалами.
Скажу избитую фразу — диалплан, это кусок творчества, сделать его можно по разному и так как этого требует задача. Поэтому ниже, это лишь пример.
Делаем таблицу domains:
domain (VARCHAR) | code (VARCHAR)
Заполняем, к примеру, вот так:
test2 | 01
test3 | 02
Код филиала можно взять конечно любой — даже 1 знак. Определяемся с выходом на филиалы. Например, у меня, выход на «город» через 9, а на филиалы я возьму 8. Вы берете то, что удобно Вам. Хоть * (звездочка).
Связываем в extconfig.conf таблицу domains с идентификатором domains. Пишем диалплан:
exten => _8XXXXX,1,NoOp(Call from ${CALLERID(all)} to filial ${EXTEN:1:2})
same => n, Set(domain=${REALTIME_FIELD(domains,code,${EXTEN:1:2},domain)})
same => n, GotoIF($[ "${domain}" = "" ]?GotoError) ; Обрабатываем не верный код филиала
same => n, Dial(PJSIP/${EXTEN:3}@${domain})
same => n, HangipИтого, набираем на телефоне, 801123 и попадаем в филиал test2 на номер 123.
Для того, чтобы было удобнее администрировать, можно добавить еще ограничение ключа:
Numbers.domain — FOREIGN KEY -> domains.domain
Это позволит не потерять домены при редактировании.
Requirements
This packages requires php-oe-json which itself will require
Tivoka which was patched for session id support on version >= 3.2.* .
Аксиома
В рамках этой статьи принимаем, что SSO реализовано и работает исключительно в рамках Intranet (в корпоративной среде), и при этом обеспечивает достаточную надёжность, отказоустойчивость и безопасность.
Белый танец. кто кого?..
Leicht versprochen, leicht gebrochen.
Задача
На входе мы имеем:
Сразу оговорюсь, что есть и более простые пути решения этой задачки, помимо описанного ниже, но мы же их не ищем. Ну и требования Заказчика были не самые однозначные.
Итак, приступаем!
Как зарегистрировать абонента?
Microsip, настройки будут выглядеть вот так:
Теперь каждый филиал может иметь свой номер 101 для директора. Разве это не прекрасно?
Кроссдоменная авторизация: часть 1 | через терни к звездам
Рано или поздно проблема кроссдоменной авторизации встает перед всеми WEB разработчиками. Существует несколько способов организации кроссдоменной авторизации:
- через iframe;
- через javascript;
- через передачу идентификатора сессии.
Скорее всего существую и другие способы, но они меня не сильно интересуют, так как я для себя выбрал последний как самый простой в реализации и поддержке. Решение этой задачки вылилось в отдельный класс, который подключается к приложению. Помимо самого класса создается общая база данных, которая будет доступна во всех приложениях. Мы сделали отдельный проект, через который происходит регистрация и управления правами пользователей. У нас существует много внутренний приложений, для которых как раз и делали общую авторизацию, поэтому пришлось писать класс полностью универсальным, и как можно больше абстрагированным от конкретной реализации драйвера базы данных: просто подключить класс и начать пользоваться. Для начала определимся с тем, что же мы ждем:
- логин и пароль вводим одни раз, а авторизуемся в нескольких приложениях;
- гибкая система прав пользователей, основанная на группах;
- сохранение информации о сессии в базе данных.
Для выполнения первого пункта мы разработали отдельное приложение, основное назначение которого — проверить правильность ввода логина и пароля. Так же через это приложение администраторы могут добавлять новых пользователей и менять права уже имеющимся. Второй пункт немного сложнее. Мы рассматривали несколько вариантов организации хранения прав пользователей, выбирали самый простой в реализации, самый гибкий и самый легкий в поддержке. Варианты были следующие:
- для каждого отдельного права создать отдельную колонку в базе данных;
- хранить права в битовых масках, внутри приложений хранить права в виде масок для проверки;
- создать отдельную таблицу с перечнем всех прав, привязка к группе осуществляется через дополнительную таблицу (т.е. организация связи многие ко многим).
Первый сразу отмели, потому что нам в наследство достались приложения, которые как раз и хранили права в таком видел. Так что мы представляем все «удобства» такого решения. А сколько «удовольствия» доставляет добавить новые права :-). Второй вариант практические приняли как стандартный для наших приложений, но в последний момент отвергли. Да, он удобен, легко установить и удалить права, но только для одного пользователя. В случае смены прав у целой группы, надо обновлять права отдельно для всех пользователей данной группы, и одним запросом к базе данных тут не обойтись. Плюс возникают сложности, как привязать смещение в маске к отдельному праву. Еще можно только догадываться, какого размера в итоге будет маска, даже если хранить маску в разных полях базы данных для каждого приложения. Поэтому методом исключения остается последний. В нем мы нашли один недостаток, с которым может вполне мириться: сложно добавить отдельные права для каждого пользователя. Если надо расширить пользователю возможности, мы просто создаем новую группу пользователей, а потом добавляем туда всех, кому надо расширить права.
Следующим пунктом было проектирование базы данных. Но сперва надо определиться с тем, каким образом будем организовывать группы разных приложений.
Разобьем список групп на зоны. Каждая зона соответствует приложению. Внутри зоны находятся группы пользователей. Внутри группы, конечно же, находятся пользователи. Все просто и логично :-).
При создании пользователя в «админке» выставляем нужные галочки для каждого приложения (в нашем случае в каждой зоне). Все.
Просто? Для нас — да.
Теперь перейдем к самой базе данных.

Я не ручаюсь за правильность проектирования, но она решает нашу задачу в полной мере.
В таблице users хранятся учетные данные пользователей: логин, хеш пароля и настоящее имя. Отсюда пользователи не должны удаляться так как пропадут привязки к приложениям. Чтобы не держать дополнительных соединений к базе данных авторизации в приложении, мы переложили это на плечи самого MySQL сервера: для каждого приложения создали отдельные таблицы, подобные users, только тип поменяли на FEDERATED.
Назначение таблиц zones, groups, rights, по-моему, понятно из названия.
В таблице sessions хранятся сессии пользователей. Идентификация сессии проходит по хешу, который хранится в массиве $_SESSION в приложении. Так же этот хеш используется для создания собственных сессий внутри приложения.
Таблица settings хранит настройки пользователей для приложений. Например, количество пунктов списка на страницу, текущая тема приложения и т.д.
Времени особо не хватает. Поэтому пока остановлюсь на этом. Во второй части будет описание класса и исходники.
Медляк. mod_auth_ntlm_winbind
Прежде чем танцевать медленный танец, придется кого-то на него пригласить, ведь в одиночку под него двигаться не считается приемлемым. Улучите момент и подойдите к приглянувшейся девушке. Собравшись танцевать медленный танец, объявите о своем намерении потенциальной партнерше прямо, без ненужного многословия. Не будьте излишне развязны и напористы, оставьте за ней решение, согласиться или нет. В последнем случае она откажется, но поблагодарит вас.
Настройка
Этого, конечно, недостаточно, потому что свежеустановленный индеец не знает нашего языка. Сконфигурируем его примерно так:
Одна сессия мультидоменного портала. как это сделать в php
Он назвал это «спецоперация»…
Прямо сейчас, на твоих глазах совершается величайшее преступление 21-го века. С 24 февраля 2022 года мы украинцы переживаем вой серен, голод, взрывы, вражьи пытки, похищения детей, насилия и смерти. Горе и страдания принесли с собой «асвабадители»…
Собачий вальс. kerberos
Це́рбер, также Ке́рбер (от др.-греч. Κέρβερος, лат. Cerberus) — в греческой мифологии порождение Тифона и Ехидны (Тартара и Геи), трёхголовый пёс, у которого из пастей течёт ядовитая смесь. Цербер охранял выход из царства мёртвых Аида, не позволяя умершим возвращаться в мир живых. Однако это удивительное по силе существо было побеждено Гераклом в одном из его подвигов.
Уверен, что не нужно напоминать про необходимость правильной настройки Kerberos для «плодотворного сотрудничества» с MSAD.
Разумеется, для установки и конфигурирования вам необходимы root’овые права на сервере. Или sudo. Или «Звоните Солу».
Собственно, где результат?
Если все сделано правильно, то у нас должны отобразиться такие endpoint в консоли астериска:
Не буду приводить всю портянку, суть видна на скрине и так. «Глобальные номера» у нас как и обычно без домена. А вот «местная нумерация» вся идет с доменном.
Обращаю внимание, что в диалплане нужно учитывать домен. Т.е., на 5ти знаки:
Dial(PJSIP/19960)
а вот на 3х знаки
Dial(PJSIP/123@test3)
Диалплан получается немного хитрый, но тем не менее, реализовать его не сложно.
Танец великих равнин. apache
Апачи – собирательное название для нескольких культурно родственных племён североамериканских индейцев, говорящих на апачских языках атабаскской ветви семьи на-дене.
Апачи создали свой собственный захватывающий танец в масках по названию гахан, которым они празднуют достижение совершеннолетия девочками. Также у апачей и поныне есть танцевальные обряды для видений и предсказаний.
Начинаем охотиться вместе с индейцами племён Апачи.
Танцуем с пингвинами. linux
Домен: Эукариоты, Царство: Животные, Подцарство: Эуметазои, Тип: Хордовые, Подтип: Позвоночные, Инфратип: Челюстноротые, Надкласс: Четвероногие, Класс: Птицы, Подкласс: Новонёбные, Отряд: Пингвинообразные, Семейство: Пингвиновые, Вид: Oracle Linux Server release 7.2
Танцуем самбу!
Са́мба (порт. samba) — бразильский танец, символ национальной идентичности бразильцев. Танец обрёл мировую известность благодаря бразильским карнавалам. Одна из разновидностей самбы вошла в обязательную пятёрку латиноамериканской программы бальных танцев. Исполняется в темпе 50-52 удара в минуту, в размере 2/4 или 4/4.
Как всем нам прекрасно известно, наша любимая Samba в серверном варианте совершенно логично разделена на три основных исполняемых модуля: (smb|nmb|winbind)d.
Теоретически нам нужен только работоспособный winbindd. Да, это всего лишь один из демонов Самбы. Но он, установленный отдельно от всего пакета, почему-то на имеющейся платформе работать не захотел, а разбираться в причинах его недовольства не захотелось уже мне.
Поэтому устанавливаемся по полной.
Тестирование
Сначала смотрим на настройки DNS, т.к. это критично для работоспособности всего решения:
Установка
Установка и настройка необходимых пакетов производится довольно просто, если «злые сетевые админы» дали вашему серверу выход в Интернет.
К сожалению, Интернет с доступом к репозиториям нужен на этапе установки, если добрые админы не установили всё нужное заблаговременно.
И всё печально, если нет ни доступа, ни установленных пакетов.
Однако будем оптимистами и, считая, что админы хотя бы на часик открыли канал, выполняем установку:
[root@my-test-server ~]# yum install krb5-workstation
Загружены модули: ulninfo
Разрешение зависимостей
--> Проверка сценария
---> Пакет krb5-workstation.x86_64 0:1.14.1-26.el7 помечен для установки
--> Обработка зависимостей: libkadm5(x86-64) = 1.14.1-26.el7 пакета: krb5-workstation-1.14.1-26.el7.x86_64
--> Обработка зависимостей: krb5-libs(x86-64) = 1.14.1-26.el7 пакета: krb5-workstation-1.14.1-26.el7.x86_64
--> Обработка зависимостей: libkadm5srv_mit.so.10(kadm5srv_mit_10_MIT)(64bit) пакета: krb5-workstation-1.14.1-26.el7.x86_64
--> Обработка зависимостей: libkadm5srv_mit.so.10()(64bit) пакета: krb5-workstation-1.14.1-26.el7.x86_64
--> Проверка сценария
---> Пакет krb5-libs.x86_64 0:1.13.2-10.el7 помечен для обновления
---> Пакет krb5-libs.x86_64 0:1.14.1-26.el7 помечен как обновление
---> Пакет libkadm5.x86_64 0:1.14.1-26.el7 помечен для установки
--> Проверка зависимостей окончена
Зависимости определены
==============================================================
Package Архитектура Версия Репозиторий Размер
==============================================================
Установка:
krb5-workstation x86_64 1.14.1-26.el7 ol7_latest 772 k
Установка зависимостей:
libkadm5 x86_64 1.14.1-26.el7 ol7_latest 172 k
Обновление зависимостей:
krb5-libs x86_64 1.14.1-26.el7 ol7_latest 741 k
Итого за операцию
==== =============================================
Установить 1 пакет ( 1 зависимый)
Обновить ( 1 зависимый)
Объем загрузки: 1.6 M
Is this ok [y/d/N]: y
Downloading packages:
No Presto metadata available for ol7_latest
(1/3): krb5-libs-1.14.1-26.el7.x86_64.rpm | 741 kB 00:00:00
(2/3): libkadm5-1.14.1-26.el7.x86_64.rpm | 172 kB 00:00:00
(3/3): krb5-workstation-1.14.1-26.el7.x86_64.rpm | 772 kB 00:00:00
--------------------------------------------------------------------------------
Общий размер 3.9 MB/s | 1.6 MB 00:00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Обновление : krb5-libs-1.14.1-26.el7.x86_64 1/4
Установка : libkadm5-1.14.1-26.el7.x86_64 2/4
Установка : krb5-workstation-1.14.1-26.el7.x86_64 3/4
Очистка : krb5-libs-1.13.2-10.el7.x86_64 4/4
Проверка : krb5-libs-1.14.1-26.el7.x86_64 1/4
Проверка : libkadm5-1.14.1-26.el7.x86_64 2/4
Проверка : krb5-workstation-1.14.1-26.el7.x86_64 3/4
Проверка : krb5-libs-1.13.2-10.el7.x86_64 4/4
Установлено:
krb5-workstation.x86_64 0:1.14.1-26.el7
Установлены зависимости:
libkadm5.x86_64 0:1.14.1-26.el7
Обновлены зависимости:
krb5-libs.x86_64 0:1.14.1-26.el7
Выполнено!Само собой, как используемый менеджер пакетов, так и их версии у вас могут быть другими, но сути дела это не меняет.
И Да, обещаю, что более таких наиполнейших листингов тривиальной установки в статье не появится.
Do you store the login password and send it to other domains ?
No, you shouldn’t store password anywhere. What is sent are tokens
identifying an already opened connection. These tokens are
often called «session ids» and have the appearance of a random hex
fingerprint string generated at login time.
Single sign-on. выводная
Я буду весьма признателен, если подскажете в комментариях более удачную конфигурацию; допускаю даже, что появилась новая механика взаимодействия AAA для связки Linux Apache MSAD, про которую я не знаю.
Спасибо!
11 Выводы по обобщенной модели
Предложенная модель дает возможность сделать масштабируемую систему авторизации. Позволяет сделать глобальное разграничение один раз и далее только корректировать, добавляя новые роли, разрешения, группы, все более детализируя доступ к каждому конкретному ресурсу каждому пользователю.
Заключение
В статье предложена универсальная модель для авторизации доступа множеству пользователей к множеству ресурсов с минимальными потерями по производительности, позволяющая делать эффективное кеширование и хранение промежуточных данных на микросервисах, для сборки результата авторизации just-in-time.
Предложена метрика (в виде коэффициента), для оценки работы авторизации микросервисов с учетом требований работы всего комплекса и показано, как он может меняться в зависимости от подхода, а именно наличия/отсутствия кеша, хранения ролей в JWT токене и т.д. Не показано, что этот коэффициент всегда растет с увеличением количества под в системе.
Предложенная модель данных позволяет разделить данные между частями микросервисной архитектуры, тем самым снизив требования к железу, дает возможность работать только с теми данными, которые нужны в конкретный момент времени конкретному сервису, не пытаться искать в огромном массиве все подряд или пытаться искать данные в полностью обобщенном хранилище.
Показано, что при малом количестве микросервисов нет смысла проводить кеширование на клиенте авторизации, так как это приведет к большей нагрузке на ЦПУ. Предоставлены данные, которые позволяют сделать вывод, что необходимо балансировать ресурсы в зависимости от размеров системы, если она слишком мала, то есть смысл нагружать больше сеть, но при увеличении и разрастании выгоднее добавить пару ядер в микросервисы, для обеспечения работы кешей и разгрузки сети, микросервисов авторизационных данных.